ముందస్తు అవసరాలు
ఈ ట్యుటోరియల్లోని ఉదాహరణలను ప్రాక్టీస్ చేయడానికి ముందు మీరు క్లయింట్తో డేటాబేస్ సర్వర్ను ఇన్స్టాల్ చేయాలి. MariaDB డేటాబేస్ సర్వర్ మరియు క్లయింట్ ఈ ట్యుటోరియల్లో ఉపయోగించబడతాయి.
1. సిస్టమ్ను నవీకరించడానికి కింది ఆదేశాలను అమలు చేయండి:
$ sudo apt-get update
2. MariaDB సర్వర్ మరియు క్లయింట్ను ఇన్స్టాల్ చేయడానికి కింది ఆదేశాన్ని అమలు చేయండి:
$ sudo apt-get install mariadb-server mariadb-client
3. MariaDB డేటాబేస్ కోసం భద్రతా స్క్రిప్ట్ను ఇన్స్టాల్ చేయడానికి కింది ఆదేశాన్ని అమలు చేయండి:
$ sudo mysql_secure_installation
4. MariaDB సర్వర్ను పునఃప్రారంభించడానికి కింది ఆదేశాన్ని అమలు చేయండి:
$ sudo /etc/init.d/mariadb పునఃప్రారంభించండి
6. MariaDB సర్వర్కు లాగిన్ చేయడానికి కింది ఆదేశాన్ని అమలు చేయండి:
$ sudo mariadb -u రూట్ -pSQL ప్రశ్న ఉదాహరణల జాబితా
- డేటాబేస్ సృష్టించండి
- పట్టికలను సృష్టించండి
- టేబుల్ పేరు పేరు మార్చండి
- పట్టికకు కొత్త నిలువు వరుసను జోడించండి
- పట్టిక నుండి నిలువు వరుసను తీసివేయండి
- పట్టికలో ఒకే వరుసను చొప్పించండి
- పట్టికలో బహుళ అడ్డు వరుసలను చొప్పించండి
- టేబుల్ నుండి అన్ని ప్రత్యేక ఫీల్డ్లను చదవండి
- టేబుల్ నుండి డేటాను ఫిల్టర్ చేసిన తర్వాత టేబుల్ చదవండి
- బూలియన్ లాజిక్ ఆధారంగా డేటాను ఫిల్టర్ చేసిన తర్వాత టేబుల్ చదవండి
- డేటా పరిధి ఆధారంగా వరుసలను ఫిల్టర్ చేసిన తర్వాత పట్టికను చదవండి
- నిర్దిష్ట నిలువు వరుసల ఆధారంగా పట్టికను క్రమబద్ధీకరించిన తర్వాత పట్టికను చదవండి.
- కాలమ్ యొక్క ప్రత్యామ్నాయ పేరును సెట్ చేయడం ద్వారా పట్టికను చదవండి
- పట్టికలోని మొత్తం వరుసల సంఖ్యను లెక్కించండి
- బహుళ పట్టికల నుండి డేటాను చదవండి
- నిర్దిష్ట ఫీల్డ్లను సమూహపరచడం ద్వారా పట్టికను చదవండి
- నకిలీ విలువలను వదిలివేసిన తర్వాత పట్టికను చదవండి
- వరుస సంఖ్యను పరిమితం చేయడం ద్వారా పట్టికను చదవండి
- పాక్షిక సరిపోలిక ఆధారంగా పట్టికను చదవండి
- టేబుల్ యొక్క నిర్దిష్ట ఫీల్డ్ మొత్తాన్ని లెక్కించండి
- నిర్దిష్ట ఫీల్డ్ యొక్క గరిష్ట మరియు కనిష్ట విలువలను కనుగొనండి
- ఫీల్డ్ యొక్క నిర్దిష్ట భాగంపై డేటాను చదవండి
- సంగ్రహణ తర్వాత టేబుల్ డేటాను చదవండి
- గణిత గణన తర్వాత టేబుల్ డేటాను చదవండి
- పట్టిక యొక్క వీక్షణను సృష్టించండి
- నిర్దిష్ట పరిస్థితి ఆధారంగా పట్టికను నవీకరించండి
- నిర్దిష్ట పరిస్థితి ఆధారంగా టేబుల్ డేటాను తొలగించండి
- పట్టిక నుండి అన్ని రికార్డులను తొలగించండి
- పట్టికను వదలండి
- డేటాబేస్ను వదలండి
డేటాబేస్ సృష్టించండి
లైబ్రరీ మేనేజ్మెంట్ సిస్టమ్ కోసం మనం ఒక సాధారణ డేటాబేస్ను రూపొందించాలని అనుకుందాం. ఈ పనిని చేయడానికి, బహుళ రిలేషనల్ టేబుల్లను కలిగి ఉండే సర్వర్లో డేటాబేస్ సృష్టించాలి. డేటాబేస్ సర్వర్కు లాగిన్ అయిన తర్వాత, మరియాడిబి డేటాబేస్ సర్వర్లో “లైబ్రరీ” అనే డేటాబేస్ను సృష్టించడానికి కింది ఆదేశాన్ని అమలు చేయండి:
సృష్టించు డేటాబేస్ గ్రంధాలయం;లైబ్రరీ డేటాబేస్ సర్వర్లో సృష్టించబడిందని అవుట్పుట్ చూపిస్తుంది:
 వివిధ రకాల డేటాబేస్ కార్యకలాపాలను నిర్వహించడానికి సర్వర్ నుండి డేటాబేస్ను ఎంచుకోవడానికి కింది ఆదేశాన్ని అమలు చేయండి:
వివిధ రకాల డేటాబేస్ కార్యకలాపాలను నిర్వహించడానికి సర్వర్ నుండి డేటాబేస్ను ఎంచుకోవడానికి కింది ఆదేశాన్ని అమలు చేయండి:
లైబ్రరీ డేటాబేస్ ఎంపిక చేయబడిందని అవుట్పుట్ చూపిస్తుంది:

పట్టికలను సృష్టించండి
డేటాను నిల్వ చేయడానికి డేటాబేస్ కోసం అవసరమైన పట్టికలను సృష్టించడం తదుపరి దశ. ట్యుటోరియల్ యొక్క ఈ భాగంలో మూడు పట్టికలు సృష్టించబడ్డాయి. ఇవి పుస్తకాలు, సభ్యులు మరియు borrow_info పట్టికలు.
- పుస్తకాల పట్టిక మొత్తం పుస్తక సంబంధిత డేటాను నిల్వ చేస్తుంది.
- సభ్యుల పట్టిక లైబ్రరీ నుండి పుస్తకాన్ని తీసుకున్న సభ్యుల గురించిన మొత్తం సమాచారాన్ని నిల్వ చేస్తుంది.
- borrow_info పట్టికలో ఏ పుస్తకం ఏ సభ్యుడు అరువుగా తీసుకున్నారనే సమాచారాన్ని నిల్వ చేస్తుంది.
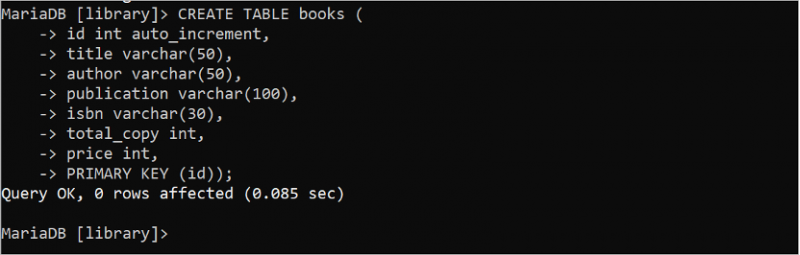
1. పుస్తకాలు పట్టిక
ఏడు ఫీల్డ్లు మరియు ఒక ప్రాథమిక కీని కలిగి ఉన్న “లైబ్రరీ” డేటాబేస్లో “పుస్తకాలు” అనే పట్టికను సృష్టించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. ఇక్కడ, “id” ఫీల్డ్ ప్రాథమిక కీ మరియు డేటా రకం పూర్ణాంకం. “id” ఫీల్డ్ కోసం auto_increment లక్షణం ఉపయోగించబడుతుంది. కాబట్టి, కొత్త అడ్డు వరుసను చొప్పించినప్పుడు ఈ ఫీల్డ్ విలువ స్వయంచాలకంగా పెరుగుతుంది. వేరియబుల్ పొడవు యొక్క స్ట్రింగ్ డేటాను నిల్వ చేయడానికి varchar డేటా రకం ఉపయోగించబడుతుంది. శీర్షిక, రచయిత, ప్రచురణ మరియు isbn ఫీల్డ్లు స్ట్రింగ్ డేటాను నిల్వ చేస్తాయి. total_copy మరియు ధర ఫీల్డ్ల యొక్క డేటా రకం పూర్ణాంకం. కాబట్టి, ఈ ఫీల్డ్లు సంఖ్యా డేటాను నిల్వ చేస్తాయి.
సృష్టించు పట్టిక పుస్తకాలు (id INT AUTO_INCREMENT ,
శీర్షిక వర్చర్ ( యాభై ) ,
రచయిత వర్చర్ ( యాభై ) ,
ప్రచురణ వర్చర్ ( 100 ) ,
isbn వర్చర్ ( 30 ) ,
మొత్తం_కాపీ INT ,
ధర INT ,
ప్రాథమిక కీ ( id ) ) ;
'పుస్తకాలు' పట్టిక విజయవంతంగా సృష్టించబడిందని అవుట్పుట్ చూపిస్తుంది:
2. సభ్యులు పట్టిక
5 ఫీల్డ్లు మరియు ఒక ప్రాథమిక కీని కలిగి ఉన్న “లైబ్రరీ” డేటాబేస్లో “సభ్యులు” అనే పట్టికను సృష్టించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. “ఐడి” ఫీల్డ్లో “పుస్తకాలు” టేబుల్ వంటి ఆటో_ఇంక్రిమెంట్ లక్షణాన్ని కలిగి ఉంది. ఇతర ఫీల్డ్ల డేటా రకం varchar. కాబట్టి, ఈ ఫీల్డ్లు స్ట్రింగ్ డేటాను నిల్వ చేస్తాయి.
సృష్టించు పట్టిక సభ్యులు (id INT AUTO_INCREMENT ,
పేరు వర్చర్ ( యాభై ) ,
చిరునామా వర్చర్ ( 200 ) ,
సంప్రదంచాల్సిన నెం వర్చర్ ( పదిహేను ) ,
ఇమెయిల్ వర్చర్ ( యాభై ) ,
ప్రాథమిక కీ ( id ) ) ;
'సభ్యుల' పట్టిక విజయవంతంగా సృష్టించబడిందని అవుట్పుట్ చూపిస్తుంది:

3. Borrow_info పట్టిక
6 ఫీల్డ్లను కలిగి ఉన్న “లైబ్రరీ” డేటాబేస్లో “borrow_info” పేరుతో పట్టికను సృష్టించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. ఇక్కడ, “id” ఫీల్డ్ ప్రాథమిక కీ, అయితే ఈ ఫీల్డ్ కోసం auto_increment లక్షణం ఉపయోగించబడదు. కాబట్టి, పట్టికలో కొత్త రికార్డ్ను చొప్పించినప్పుడు ఈ ఫీల్డ్లో ఒక ప్రత్యేక విలువ మానవీయంగా చొప్పించబడుతుంది. book_id మరియు member_id ఫీల్డ్లు ఈ పట్టికకు విదేశీ కీలు; అవి 'పుస్తకాలు' పట్టిక మరియు 'సభ్యుల' పట్టిక యొక్క ప్రాథమిక కీ. borrow_date మరియు return_date ఫీల్డ్ల డేటా రకం తేదీ. కాబట్టి, ఈ రెండు ఫీల్డ్లు తేదీ విలువను “YYYY-MM-DD” ఆకృతిలో నిల్వ చేస్తాయి.
సృష్టించు పట్టిక అరువు_సమాచారం (id INT ,
రుణం_తేదీ DATE ,
పుస్తకం_ఐడి INT ,
సభ్యుడు_ఐడి INT ,
తిరిగి వచ్చు తేదీ DATE ,
స్థితి వర్చర్ ( 10 ) ,
ప్రాథమిక కీ ( id ) ,
విదేశీ కీ ( పుస్తకం_ఐడి ) ప్రస్తావనలు పుస్తకాలు ( id ) ,
విదేశీ కీ ( సభ్యుడు_ఐడి ) ప్రస్తావనలు సభ్యులు ( id ) ) ;
“borrow_info” పట్టిక విజయవంతంగా సృష్టించబడిందని అవుట్పుట్ చూపిస్తుంది:

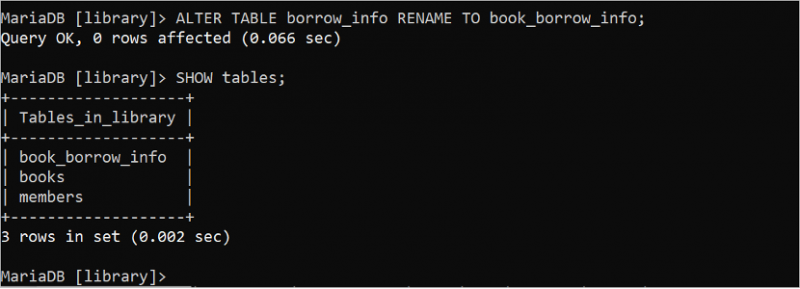
టేబుల్ పేరు పేరు మార్చండి
ALTER TABLE స్టేట్మెంట్ని SQL స్టేట్మెంట్లలో బహుళ ప్రయోజనాల కోసం ఉపయోగించవచ్చు. “borrow_info” పట్టిక పేరును “book_borrow_info”గా మార్చడానికి క్రింది ALTER TABLE స్టేట్మెంట్ను అమలు చేయండి. తరువాత, పట్టిక పేరు మార్చబడిందో లేదో తనిఖీ చేయడానికి SHOW పట్టికల ప్రకటనను ఉపయోగించవచ్చు.
ALTER పట్టిక అరువు_సమాచారం RENAME TO పుస్తకం_అరువు_సమాచారం;చూపించు పట్టికలు ;
పట్టిక పేరు విజయవంతంగా మార్చబడిందని మరియు borrow_info పట్టిక పేరు book_borrow_infoగా మార్చబడిందని అవుట్పుట్ చూపిస్తుంది:
పట్టికకు కొత్త నిలువు వరుసను జోడించండి
పట్టికను సృష్టించిన తర్వాత ఒకటి లేదా అంతకంటే ఎక్కువ నిలువు వరుసలను జోడించడానికి లేదా తొలగించడానికి ALTER TABLE స్టేట్మెంట్ ఉపయోగించబడుతుంది. కింది ALTER TABLE స్టేట్మెంట్ టేబుల్ మెంబర్లకు “స్టేటస్” అనే కొత్త ఫీల్డ్ని జోడిస్తుంది. పట్టిక నిర్మాణం మార్చబడిందో లేదో చూపించడానికి DESCRIBE స్టేట్మెంట్ ఉపయోగించబడుతుంది.
ALTER పట్టిక సభ్యులు జోడించు స్థితి వర్చర్ ( 10 ) ;వివరించండి సభ్యులు;
'సభ్యుల' పట్టికకు 'స్టేటస్' అనే కొత్త నిలువు వరుస జోడించబడిందని అవుట్పుట్ చూపిస్తుంది మరియు పట్టిక యొక్క డేటా రకం varchar:

పట్టిక నుండి నిలువు వరుసను తీసివేయండి
కింది ALTER TABLE స్టేట్మెంట్ 'సభ్యులు' పట్టిక నుండి 'స్థితి' అనే ఫీల్డ్ను తొలగిస్తుంది. పట్టిక నిర్మాణం మార్చబడిందో లేదో చూపించడానికి DESCRIBE స్టేట్మెంట్ ఉపయోగించబడుతుంది.
ALTER పట్టిక సభ్యులు డ్రాప్ చేయండి కాలమ్ స్థితి ;వివరించండి సభ్యులు;
'సభ్యుల' పట్టిక నుండి 'స్టేటస్' నిలువు వరుస తీసివేయబడిందని అవుట్పుట్ చూపిస్తుంది:

పట్టికలో ఒకే వరుసను చొప్పించండి
పట్టికలో ఒకటి లేదా అంతకంటే ఎక్కువ అడ్డు వరుసలను చొప్పించడానికి INSERT INTO స్టేట్మెంట్ ఉపయోగించబడుతుంది. 'పుస్తకాలు' పట్టికలో ఒకే అడ్డు వరుసను చొప్పించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. ఇక్కడ, 'id' ఫీల్డ్ ఈ ప్రశ్న నుండి విస్మరించబడింది ఎందుకంటే ఇది ఆటో-ఇంక్రిమెంట్ అట్రిబ్యూట్ కోసం కొత్త రికార్డ్ను చొప్పించినప్పుడు అది స్వయంచాలకంగా రికార్డ్లోకి చొప్పించబడుతుంది. INSERT స్టేట్మెంట్లో ఈ ఫీల్డ్ ఉపయోగించబడితే, విలువ తప్పనిసరిగా NULL అయి ఉండాలి.
చొప్పించు INTO పుస్తకాలు ( శీర్షిక , రచయిత , ప్రచురణ , isbn , మొత్తం_కాపీ , ధర )విలువలు ( '10 నిమిషాల్లో SQL' , 'బెన్ ఫోర్టా' , 'సామ్స్ పబ్లిషింగ్' , '784534235' , 5 , 39 ) ;
'పుస్తకాలు' పట్టికకు రికార్డ్ విజయవంతంగా జోడించబడిందని అవుట్పుట్ చూపిస్తుంది:

ప్రతి ఫీల్డ్ విలువ ప్రత్యేకంగా కేటాయించబడిన SET నిబంధనను ఉపయోగించి డేటాను పట్టికలో చేర్చవచ్చు. INSERT INTO మరియు SET నిబంధనలను ఉపయోగించి 'సభ్యులు' పట్టికలో ఒకే అడ్డు వరుసను చొప్పించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. 'id' ఫీల్డ్ కూడా ఇదే కారణంతో మునుపటి ఉదాహరణ వలె ఈ ప్రశ్నలో విస్మరించబడింది.
చొప్పించు INTO సభ్యులుసెట్ పేరు = 'జాన్ సినా' , చిరునామా = '34, ధన్మొండి 9/A, ఢాకా' , సంప్రదంచాల్సిన నెం = '+14844731336' , ఇమెయిల్ = 'john@gmail.com' ;
సభ్యుల పట్టికకు రికార్డ్ విజయవంతంగా జోడించబడిందని అవుట్పుట్ చూపిస్తుంది:

“book_borrow_info” పట్టికలో ఒకే అడ్డు వరుసను చొప్పించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి:
చొప్పించు INTO పుస్తకం_రుణం_సమాచారం ( id , రుణం_తేదీ , పుస్తకం_ఐడి , సభ్యుడు_ఐడి , తిరిగి వచ్చు తేదీ , స్థితి )విలువలు ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , 'అరువు' ) ;
“book_borrow_info” పట్టికకు రికార్డ్ జోడించబడిందని అవుట్పుట్ చూపిస్తుంది:

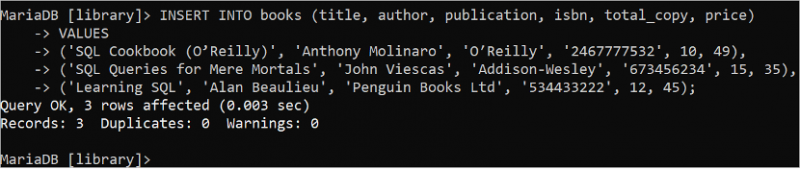
పట్టికలో బహుళ అడ్డు వరుసలను చొప్పించండి
కొన్నిసార్లు, దీనికి ఒకే ఇన్సర్ట్ ఇన్టు స్టేట్మెంట్ని ఉపయోగించి ఒకేసారి అనేక రికార్డులను జోడించడం అవసరం. ఒకే ఇన్సర్ట్ ఇన్టు స్టేట్మెంట్ని ఉపయోగించి “పుస్తకాలు” పట్టికలో మూడు రికార్డులను చొప్పించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి. ఈ సందర్భంలో, VALUES నిబంధన ఒక సారి ఉపయోగించబడుతుంది మరియు ప్రతి రికార్డ్ యొక్క డేటా కామాతో వేరు చేయబడుతుంది.
చొప్పించు INTO పుస్తకాలు ( శీర్షిక , రచయిత , ప్రచురణ , isbn , మొత్తం_కాపీ , ధర )విలువలు
( 'SQL కుక్బుక్ (ఓ'రైల్లీ)' , 'ఆంథోనీ మోలినారో' , 'ఓ'రైల్లీ' , '2467777532' , 10 , 49 ) ,
( 'మేరే మానవుల కోసం SQL ప్రశ్నలు' , 'జాన్ వీస్కాస్' , 'అడిసన్-వెస్లీ' , '673456234' , పదిహేను , 35 ) ,
( 'నేర్చుకుంటున్న SQL' , 'అలన్ బ్యూలీయు' , 'పెంగ్విన్ బుక్స్ లిమిటెడ్' , '534433222' , 12 , నాలుగు ఐదు ) ;
'పుస్తకాలు' పట్టికకు మూడు రికార్డులు జోడించబడిందని అవుట్పుట్ చూపిస్తుంది:
టేబుల్ నుండి అన్ని ప్రత్యేక ఫీల్డ్లను చదవండి
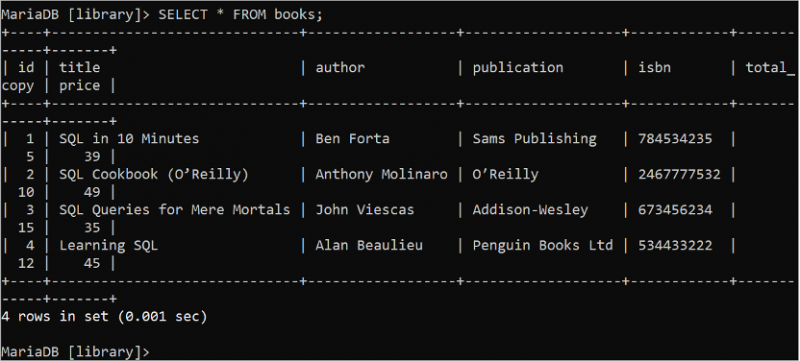
'డేటాబేస్' పట్టిక నుండి డేటాను చదవడానికి SELECT స్టేట్మెంట్ ఉపయోగించబడుతుంది. SELECT స్టేట్మెంట్లోని పట్టికలోని అన్ని ఫీల్డ్లను సూచించడానికి “*” గుర్తు ఉపయోగించబడుతుంది. పుస్తకాల పట్టిక యొక్క అన్ని రికార్డులను చదవడానికి క్రింది SQL ఆదేశాన్ని అమలు చేయండి:
ఎంచుకోండి * నుండి పుస్తకాలు;అవుట్పుట్ 4 రికార్డులను కలిగి ఉన్న పుస్తకాల పట్టిక యొక్క అన్ని రికార్డులను చూపుతుంది:
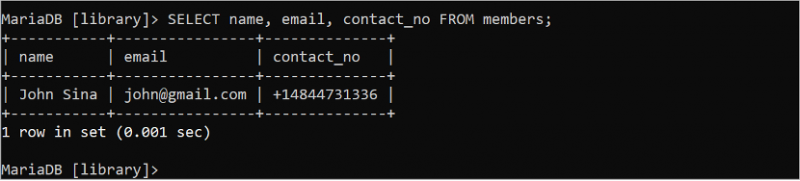
'సభ్యుల' పట్టిక యొక్క మూడు ఫీల్డ్ల యొక్క అన్ని రికార్డులను చదవడానికి క్రింది SQL ఆదేశాన్ని అమలు చేయండి:
ఎంచుకోండి పేరు , ఇమెయిల్ , సంప్రదంచాల్సిన నెం నుండి సభ్యులు;అవుట్పుట్ 'సభ్యుల' పట్టిక యొక్క మూడు ఫీల్డ్ల యొక్క అన్ని రికార్డులను చూపుతుంది:
టేబుల్ నుండి డేటాను ఫిల్టర్ చేసిన తర్వాత టేబుల్ చదవండి
ఒకటి లేదా అంతకంటే ఎక్కువ షరతుల ఆధారంగా పట్టిక నుండి డేటాను చదవడానికి WHERE నిబంధన ఉపయోగించబడుతుంది. రచయిత పేరు “జాన్ వీస్కాస్” ఉన్న “పుస్తకాల” పట్టికలోని అన్ని ఫీల్డ్ల రికార్డులను చదవడానికి క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ రచయిత = 'జాన్ వీస్కాస్' ;'పుస్తకాలు' పట్టిక అవుట్పుట్లో చూపబడిన WHERE నిబంధన యొక్క స్థితికి సరిపోలే ఒక రికార్డ్ను కలిగి ఉంది:

బూలియన్ లాజిక్ ఆధారంగా డేటాను ఫిల్టర్ చేసిన తర్వాత టేబుల్ చదవండి
బూలియన్ మరియు లాజిక్ అనేది అన్ని షరతులు ఒప్పు అని తిరిగి వచ్చినట్లయితే, WHERE క్లాజ్లో బహుళ షరతులను నిర్వచించడానికి ఉపయోగించబడుతుంది. టోటల్_కాపీ ఫీల్డ్ విలువ 10 కంటే ఎక్కువ మరియు లాజికల్ AND ఉపయోగించి ధర ఫీల్డ్ విలువ 45 కంటే తక్కువగా ఉన్న “పుస్తకాలు” పట్టికలోని అన్ని ఫీల్డ్ల రికార్డులను చదవడానికి క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ మొత్తం_కాపీ > 10 మరియు ధర < నాలుగు ఐదు ;పుస్తకాల పట్టికలో అవుట్పుట్లో చూపబడిన WHERE నిబంధన యొక్క స్థితికి సరిపోలే ఒక రికార్డ్ ఉంది:

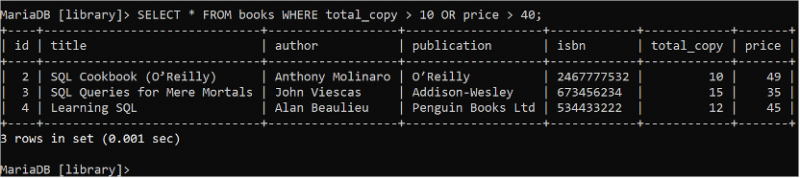
బూలియన్ OR లాజిక్ అనేది షరతుల్లో ఏదైనా సరే అని తిరిగి వచ్చినట్లయితే, WHERE క్లాజ్లో బహుళ షరతులను నిర్వచించడానికి ఉపయోగించబడుతుంది. టోటల్_కాపీ ఫీల్డ్ విలువ 10 కంటే ఎక్కువ లేదా ధర ఫీల్డ్ విలువ 40 కంటే ఎక్కువ ఉన్న “పుస్తకాలు” పట్టికలోని అన్ని ఫీల్డ్ల రికార్డులను చదవడానికి క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ మొత్తం_కాపీ > 10 లేదా ధర > 40 ;పుస్తకాల పట్టికలో అవుట్పుట్లో చూపబడిన WHERE నిబంధన యొక్క స్థితికి సరిపోలే మూడు రికార్డులు ఉన్నాయి:
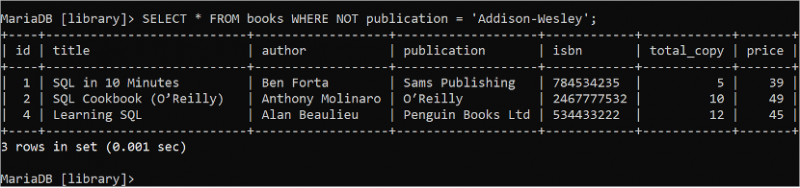
షరతు నిజం అయినప్పుడు తప్పుని తిరిగి ఇవ్వడానికి బూలియన్ నాట్ లాజిక్ ఉపయోగించబడుతుంది మరియు షరతు తప్పు అయినప్పుడు నిజాన్ని అందిస్తుంది. రచయిత ఫీల్డ్ విలువ “అడిసన్-వెస్లీ” లేని “పుస్తకాలు” పట్టికలోని అన్ని ఫీల్డ్ల రికార్డులను చదవడానికి క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ కాదు రచయిత = 'అడిసన్-వెస్లీ' ;'పుస్తకాలు' పట్టికలో అవుట్పుట్లో చూపబడిన WHERE నిబంధన యొక్క స్థితికి సరిపోలే మూడు రికార్డ్లు ఉన్నాయి:
డేటా పరిధి ఆధారంగా వరుసలను ఫిల్టర్ చేసిన తర్వాత పట్టికను చదవండి
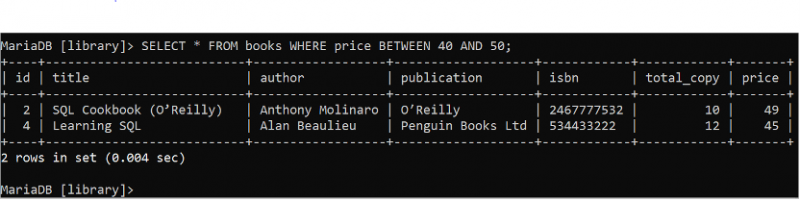
డేటాబేస్ పట్టిక నుండి డేటా పరిధిని చదవడానికి BETWEEN నిబంధన ఉపయోగించబడుతుంది. ధర ఫీల్డ్ విలువ 40 నుండి 50 మధ్య ఉన్న “పుస్తకాలు” పట్టికలోని అన్ని ఫీల్డ్ల రికార్డులను చదవడానికి క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ ధర మధ్య 40 మరియు యాభై ;పుస్తకాల పట్టికలో అవుట్పుట్లో చూపబడిన WHERE నిబంధన యొక్క స్థితికి సరిపోలే రెండు రికార్డులు ఉన్నాయి. ధర విలువల పుస్తకాలు, 39 మరియు 35, ఫలితం సెట్ నుండి విస్మరించబడ్డాయి ఎందుకంటే అవి పరిధికి దూరంగా ఉన్నాయి.
పట్టికను క్రమబద్ధీకరించిన తర్వాత పట్టికను చదవండి
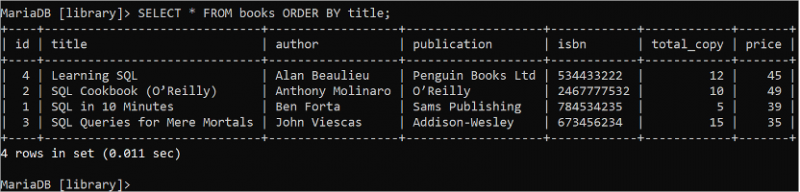
SELECT స్టేట్మెంట్ యొక్క ఫలిత సమితిని ఆరోహణ లేదా అవరోహణ క్రమంలో క్రమబద్ధీకరించడానికి నిబంధన ద్వారా ఆర్డర్ ఉపయోగించబడుతుంది. ASC లేదా DESC లేకుండా ORDER BY నిబంధనను ఉపయోగించినట్లయితే ఫలితం సెట్ డిఫాల్ట్గా ఆరోహణ క్రమంలో క్రమబద్ధీకరించబడుతుంది. కింది SELECT స్టేట్మెంట్ టైటిల్ ఫీల్డ్ ఆధారంగా పుస్తకాల పట్టిక నుండి క్రమబద్ధీకరించబడిన రికార్డులను చదువుతుంది:
ఎంచుకోండి * నుండి పుస్తకాలు ఆర్డర్ ద్వారా శీర్షిక;'పుస్తకాలు' పట్టిక యొక్క శీర్షిక ఫీల్డ్ యొక్క డేటా అవుట్పుట్లో ఆరోహణ క్రమంలో క్రమబద్ధీకరించబడింది. 'పుస్తకాలు' పట్టిక యొక్క శీర్షిక ఫీల్డ్ను ఆరోహణ క్రమంలో క్రమబద్ధీకరించినట్లయితే, 'లెర్నింగ్ SQL' పుస్తకం మొదట అక్షర క్రమంలో వస్తుంది.
కాలమ్ యొక్క ప్రత్యామ్నాయ పేరును సెట్ చేయడం ద్వారా పట్టికను చదవండి
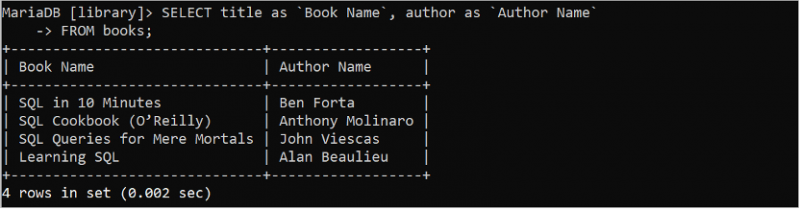
ఫలితాన్ని మరింత చదవగలిగేలా చేయడానికి ప్రశ్నలో నిలువు వరుస యొక్క ప్రత్యామ్నాయ పేరు ఉపయోగించబడుతుంది. ప్రత్యామ్నాయ పేరు 'AS' కీవర్డ్ ఉపయోగించి సెట్ చేయబడింది. కింది SQL స్టేట్మెంట్ ప్రత్యామ్నాయ పేర్లను సెట్ చేయడం ద్వారా టైటిల్ మరియు రచయిత ఫీల్డ్ల విలువలను అందిస్తుంది.
ఎంచుకోండి శీర్షిక AS `పుస్తకం పేరు` , రచయిత AS `రచయిత పేరు`నుండి పుస్తకాలు;
టైటిల్ ఫీల్డ్ 'పుస్తక పేరు' అనే ప్రత్యామ్నాయ పేరుతో ప్రదర్శించబడుతుంది మరియు అవుట్పుట్లో 'రచయిత పేరు' అనే ప్రత్యామ్నాయ పేరుతో రచయిత ఫీల్డ్ ప్రదర్శించబడుతుంది.
పట్టికలోని మొత్తం వరుసల సంఖ్యను లెక్కించండి
COUNT() అనేది నిర్దిష్ట ఫీల్డ్ లేదా అన్ని ఫీల్డ్ల ఆధారంగా మొత్తం వరుసల సంఖ్యను లెక్కించడానికి ఉపయోగించే SQL యొక్క మొత్తం ఫంక్షన్. అన్ని ఫీల్డ్లను సూచించడానికి “*” చిహ్నం ఉపయోగించబడుతుంది మరియు పట్టికలోని అన్ని రికార్డులను లెక్కించడానికి COUNT(*) ఉపయోగించబడుతుంది.
కింది ప్రశ్న పుస్తకాల పట్టిక మొత్తం రికార్డులను గణిస్తుంది:
ఎంచుకోండి COUNT ( * ) AS `మొత్తం పుస్తకాలు` నుండి పుస్తకాలు;'పుస్తకాలు' పట్టికలోని నాలుగు రికార్డులు అవుట్పుట్లో చూపబడ్డాయి:

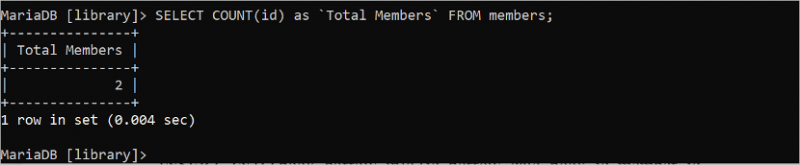
కింది ప్రశ్న 'ఐడి' ఫీల్డ్ ఆధారంగా 'సభ్యుల' పట్టిక యొక్క మొత్తం అడ్డు వరుసలను గణిస్తుంది:
ఎంచుకోండి COUNT ( id ) AS `మొత్తం సభ్యులు` నుండి సభ్యులు;'సభ్యులు' పట్టికలో అవుట్పుట్లో ముద్రించబడిన రెండు id విలువలు ఉన్నాయి:
బహుళ పట్టికల నుండి డేటాను చదవండి
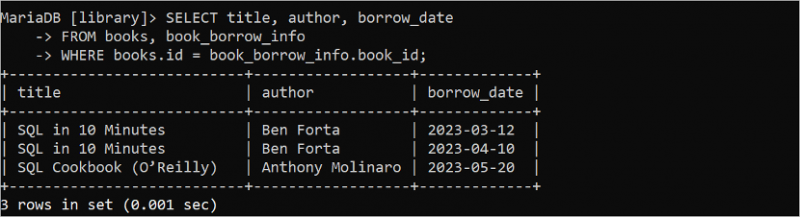
మునుపటి SELECT స్టేట్మెంట్లు ఒకే టేబుల్ నుండి డేటాను తిరిగి పొందాయి. కానీ రెండు లేదా అంతకంటే ఎక్కువ పట్టికల నుండి డేటాను తిరిగి పొందడానికి SELECT స్టేట్మెంట్ను ఉపయోగించవచ్చు. కింది SELECT ప్రశ్న 'పుస్తకాలు' పట్టిక నుండి శీర్షిక మరియు రచయిత ఫీల్డ్ల విలువలను మరియు 'book_borrow_info' పట్టిక నుండి రుణం_తేదీని చదువుతుంది.
ఎంచుకోండి శీర్షిక , రచయిత , రుణం_తేదీనుండి పుస్తకాలు , పుస్తకం_రుణం_సమాచారం
ఎక్కడ పుస్తకాలు . id = పుస్తకం_రుణం_సమాచారం . పుస్తకం_ఐడి;
క్రింది అవుట్పుట్ 'SQL ఇన్ 10 నిమిషాల' పుస్తకం రెండు సార్లు అరువు తీసుకోబడిందని మరియు 'SQL కుక్బుక్ (ఓ'రైల్లీ)' పుస్తకం ఒక సారి అరువు తీసుకోబడిందని చూపిస్తుంది:
ఈ ట్యుటోరియల్లో వివరించబడని INNER JOIN, OUTER JOIN మొదలైన వివిధ రకాల జాయిన్లను ఉపయోగించి బహుళ పట్టికల నుండి డేటాను తిరిగి పొందవచ్చు.
నిర్దిష్ట ఫీల్డ్లను సమూహపరచడం ద్వారా పట్టికను చదవండి
ఒకటి లేదా అంతకంటే ఎక్కువ ఫీల్డ్ల ఆధారంగా వరుసలను సమూహపరచడం ద్వారా పట్టిక నుండి రికార్డులను చదవడానికి GROUP BY నిబంధన ఉపయోగించబడుతుంది. ఈ రకమైన ప్రశ్నను సారాంశ ప్రశ్న అంటారు. GROUP BY నిబంధన యొక్క ఉపయోగాన్ని తనిఖీ చేయడానికి మీరు పట్టికలలో బహుళ అడ్డు వరుసలను చొప్పించవలసి ఉంటుంది. “సభ్యుల” పట్టికలో ఒక రికార్డ్ను మరియు “book_borrow_info” పట్టికలో రెండు రికార్డులను చొప్పించడానికి క్రింది INSERT స్టేట్మెంట్లను అమలు చేయండి.
చొప్పించు INTO సభ్యులుసెట్ పేరు = 'షీ హసన్' , చిరునామా = '11/A, జిగటోలా, ఢాకా' , సంప్రదంచాల్సిన నెం = '+8801734563423' , ఇమెయిల్ = 'she@gmail.com' ;
చొప్పించు INTO పుస్తకం_రుణం_సమాచారం ( id , రుణం_తేదీ , పుస్తకం_ఐడి , సభ్యుడు_ఐడి , తిరిగి వచ్చు తేదీ , స్థితి )
విలువలు ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , 'తిరిగి' ) ;
చొప్పించు INTO పుస్తకం_రుణం_సమాచారం ( id , రుణం_తేదీ , పుస్తకం_ఐడి , సభ్యుడు_ఐడి , తిరిగి వచ్చు తేదీ , స్థితి )
విలువలు ( 3 , '2023-05-20' , 2 , 1 , '2023-05-30' , 'అరువు' ) ;
మునుపటి ప్రశ్నలను అమలు చేయడం ద్వారా డేటాను చొప్పించిన తర్వాత, కింది SELECT స్టేట్మెంట్ను అమలు చేయండి, ఇది GROUP BY నిబంధనను ఉపయోగించి ప్రతి సభ్యుని ఆధారంగా అరువు తీసుకున్న పుస్తకాలు మరియు సభ్యుని పేరు మొత్తం లెక్కించబడుతుంది. ఇక్కడ, GROUP BY నిబంధనను ఉపయోగించి రికార్డ్లను మళ్లీ సమూహపరచడానికి ఉపయోగించే ఫీల్డ్లో COUNT() ఫంక్షన్ పని చేస్తుంది. 'సభ్యులు' పట్టిక యొక్క book_id ఫీల్డ్ ఇక్కడ గ్రూపింగ్ కోసం ఉపయోగించబడుతుంది.
ఎంచుకోండి COUNT ( పుస్తకం_ఐడి ) AS `మొత్తం పుస్తకం అరువుగా తీసుకోబడింది` , పేరు AS `సభ్యుని పేరు` నుండి పుస్తకాలు , సభ్యులు , పుస్తకం_రుణం_సమాచారం ఎక్కడ పుస్తకాలు . id = పుస్తకం_రుణం_సమాచారం . పుస్తకం_ఐడి మరియు సభ్యులు . id = పుస్తకం_రుణం_సమాచారం . సభ్యుడు_ఐడి సమూహం ద్వారా పుస్తకం_రుణం_సమాచారం . సభ్యుడు_ఐడి;పుస్తకాల డేటా ప్రకారం, “సభ్యులు” మరియు “book_borrow_info” పట్టికలు, “జాన్ సినా” 2 పుస్తకాలు మరియు “ఎల్లా హసన్” 1 పుస్తకాన్ని అరువు తెచ్చుకున్నారు.

నకిలీ విలువలను వదిలివేసిన తర్వాత పట్టికను చదవండి
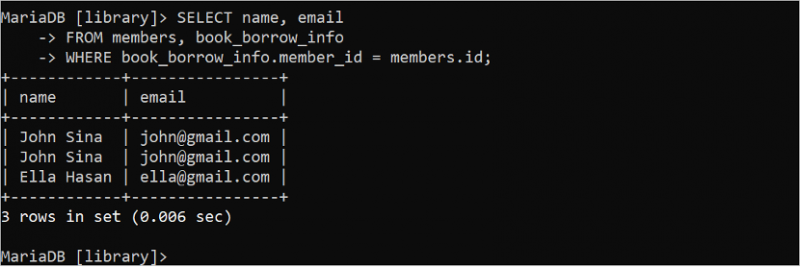
కొన్నిసార్లు, అనవసరమైన పట్టిక డేటా ఆధారంగా SELECT స్టేట్మెంట్ ఫలితాల సెట్లో నకిలీ డేటా రూపొందించబడుతుంది. ఉదాహరణకు, కింది SELECT స్టేట్మెంట్ “book_borrow_info” పట్టిక డేటా కోసం నకిలీ రికార్డులను అందిస్తుంది.
ఎంచుకోండి పేరు , ఇమెయిల్నుండి సభ్యులు , పుస్తకం_రుణం_సమాచారం
ఎక్కడ పుస్తకం_రుణం_సమాచారం . సభ్యుడు_ఐడి = సభ్యులు . id;
అవుట్పుట్లో, 'జాన్ సినా' సభ్యుడు రెండు పుస్తకాలను తీసుకున్నందున అదే రికార్డ్ రెండుసార్లు కనిపిస్తుంది. ఈ సమస్యను DISTINCT కీవర్డ్ ఉపయోగించి పరిష్కరించవచ్చు. ఇది ప్రశ్న ఫలితం నుండి నకిలీ రికార్డులను తొలగిస్తుంది.
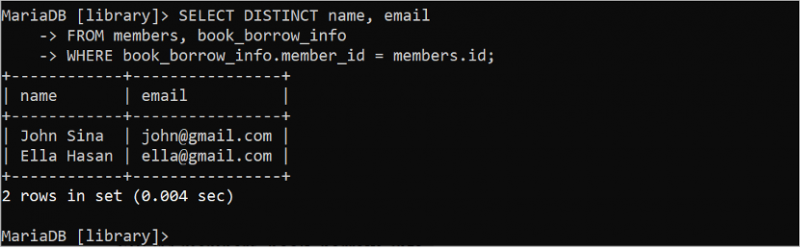
ప్రశ్నలోని DISTINCT కీవర్డ్ని ఉపయోగించి నకిలీ విలువలను వదిలివేసిన తర్వాత క్రింది SELECT స్టేట్మెంట్ 'సభ్యులు' మరియు 'book_borrow_info' పట్టికల నుండి సెట్ చేయబడిన ఫలితం యొక్క ప్రత్యేక రికార్డ్లను రూపొందిస్తుంది.
ఎంచుకోండి విభిన్న పేరు , ఇమెయిల్నుండి సభ్యులు , పుస్తకం_రుణం_సమాచారం
ఎక్కడ పుస్తకం_రుణం_సమాచారం . సభ్యుడు_ఐడి = సభ్యులు . id;
ఫలిత సెట్ నుండి నకిలీ విలువ తీసివేయబడిందని అవుట్పుట్ చూపిస్తుంది:
వరుస సంఖ్యను పరిమితం చేయడం ద్వారా పట్టికను చదవండి
కొన్నిసార్లు, ఇది వరుస సంఖ్యను పరిమితం చేయడం ద్వారా డేటాబేస్ పట్టిక నుండి ఫలితం సెట్ ప్రారంభం నుండి నిర్దిష్ట సంఖ్యలో రికార్డ్లను చదవడం, ఫలితం సెట్ ముగింపు లేదా ఫలితం మధ్యలో చదవడం అవసరం. ఇది అనేక విధాలుగా చేయవచ్చు. అడ్డు వరుసలను పరిమితం చేసే ముందు, పుస్తకాల పట్టికలో ఎన్ని రికార్డులు ఉన్నాయో తనిఖీ చేయడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి:
ఎంచుకోండి * నుండి పుస్తకాలు;పుస్తకాల పట్టికలో నాలుగు రికార్డులు ఉన్నాయని అవుట్పుట్ చూపిస్తుంది:

కింది SELECT స్టేట్మెంట్ 2 విలువతో LIMIT నిబంధనను ఉపయోగించి “పుస్తకాలు” పట్టిక నుండి మొదటి రెండు రికార్డ్లను చదువుతుంది:
ఎంచుకోండి * నుండి పుస్తకాలు పరిమితి 2 ;అవుట్పుట్లో చూపబడిన “పుస్తకాల” పట్టిక యొక్క మొదటి రెండు రికార్డ్లు తిరిగి పొందబడ్డాయి:

FETCH నిబంధన అనేది LIMIT నిబంధన యొక్క ప్రత్యామ్నాయం మరియు దాని ఉపయోగం క్రింది SELECT స్టేట్మెంట్లో చూపబడింది. SELECT స్టేట్మెంట్లోని FETCH FIRST 3 రోలు మాత్రమే నిబంధనను ఉపయోగించి “పుస్తకాలు” పట్టిక యొక్క మొదటి 3 రికార్డ్లు తిరిగి పొందబడతాయి:
ఎంచుకోండి * నుండి పుస్తకాలు FETCH ప్రధమ 3 వరుసలు మాత్రమే ;అవుట్పుట్ 'పుస్తకాల' పట్టిక యొక్క మొదటి 3 రికార్డులను చూపుతుంది:

3 నుంచి రెండు రికార్డులు RD కింది SELECT స్టేట్మెంట్ను అమలు చేయడం ద్వారా పుస్తకాల పట్టిక వరుస తిరిగి పొందబడుతుంది. LIMIT నిబంధన ఇక్కడ 2, 2 విలువతో ఉపయోగించబడుతుంది, ఇక్కడ మొదటి 2 0 నుండి లెక్కించడం ప్రారంభించే పట్టిక వరుస యొక్క ప్రారంభ స్థానాన్ని నిర్వచిస్తుంది మరియు రెండవ 2 ప్రారంభ స్థానం నుండి లెక్కించడం ప్రారంభించే వరుసల సంఖ్యను నిర్వచిస్తుంది.
ఎంచుకోండి * నుండి పుస్తకాలు పరిమితి 2 , 2 ;మునుపటి ప్రశ్నను అమలు చేసిన తర్వాత క్రింది అవుట్పుట్ కనిపిస్తుంది:

స్వయంచాలకంగా పెంచబడిన ప్రాథమిక కీ విలువ ఆధారంగా మరియు LIMIT నిబంధనను ఉపయోగించి పట్టికను అవరోహణ క్రమంలో క్రమబద్ధీకరించడం ద్వారా పట్టిక చివర నుండి రికార్డులను చదవవచ్చు. 'పుస్తకాలు' పట్టిక నుండి చివరి 2 రికార్డ్లను చదివే క్రింది SELECT స్టేట్మెంట్ను అమలు చేయండి. ఇక్కడ, ఫలితం సెట్ 'id' ఫీల్డ్ ఆధారంగా అవరోహణ క్రమంలో క్రమబద్ధీకరించబడింది.
ఎంచుకోండి * నుండి పుస్తకాలు ఆర్డర్ ద్వారా id DESC పరిమితి 2 ;పుస్తకాల పట్టిక యొక్క చివరి రెండు రికార్డులు క్రింది అవుట్పుట్లో చూపబడ్డాయి:

పాక్షిక సరిపోలిక ఆధారంగా పట్టికను చదవండి
పాక్షిక సరిపోలిక ద్వారా పట్టిక నుండి రికార్డులను తిరిగి పొందడానికి '%' చిహ్నంతో LIKE నిబంధన ఉపయోగించబడుతుంది. కింది SELECT స్టేట్మెంట్ 'పుస్తకాలు' పట్టిక నుండి రికార్డ్లను శోధిస్తుంది, ఇక్కడ రచయిత ఫీల్డ్ విలువ ప్రారంభంలో 'జాన్'ని కలిగి ఉన్న లైక్ నిబంధనను ఉపయోగించి శోధిస్తుంది. ఇక్కడ, శోధన స్ట్రింగ్ చివరిలో “%” గుర్తు ఉపయోగించబడుతుంది.
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ రచయిత ఇష్టం 'జాన్%' ;రచయిత ఫీల్డ్ విలువ ప్రారంభంలో 'జాన్' స్ట్రింగ్ను కలిగి ఉన్న 'పుస్తకాల' పట్టికలో ఒక రికార్డ్ మాత్రమే ఉంది.

కింది SELECT స్టేట్మెంట్ 'పుస్తకాలు' పట్టిక నుండి రికార్డులను శోధిస్తుంది, ఇక్కడ ప్రచురణ ఫీల్డ్ విలువ చివరిలో 'Ltd'ని కలిగి ఉంటుంది, LIKE నిబంధనను ఉపయోగించి. ఇక్కడ, శోధన స్ట్రింగ్ ప్రారంభంలో “%” గుర్తు ఉపయోగించబడుతుంది:
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ ప్రచురణ ఇష్టం '% లిమిటెడ్' ;పబ్లికేషన్ ఫీల్డ్ చివరిలో 'లిమిటెడ్' స్ట్రింగ్ను కలిగి ఉన్న 'పుస్తకాల' పట్టికలో ఒక రికార్డ్ మాత్రమే ఉంది.

కింది SELECT స్టేట్మెంట్ 'పుస్తకాలు' పట్టిక నుండి రికార్డ్లను శోధిస్తుంది, ఇక్కడ టైటిల్ ఫీల్డ్లో 'ప్రశ్నలు' ఎక్కడైనా LIKE నిబంధనను ఉపయోగించి విలువలో ఉంటాయి. ఇక్కడ, '%' గుర్తు శోధన స్ట్రింగ్ యొక్క రెండు వైపులా ఉపయోగించబడుతుంది:
ఎంచుకోండి * నుండి పుస్తకాలు ఎక్కడ శీర్షిక ఇష్టం '%ప్రశ్నలు%' ;టైటిల్ ఫీల్డ్లో 'క్వరీస్' స్ట్రింగ్ను కలిగి ఉన్న 'పుస్తకాల' పట్టికలో ఒక రికార్డ్ మాత్రమే ఉంది.

టేబుల్ యొక్క నిర్దిష్ట ఫీల్డ్ మొత్తాన్ని లెక్కించండి
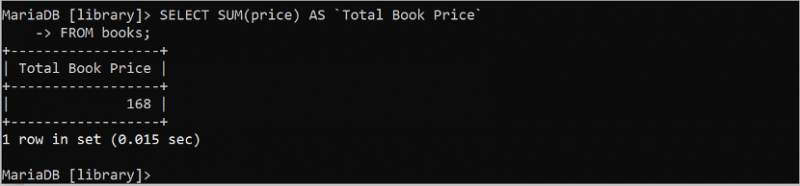
SUM() అనేది SQL యొక్క మరొక ఉపయోగకరమైన మొత్తం ఫంక్షన్, ఇది పట్టికలోని ఏదైనా సంఖ్యా ఫీల్డ్ యొక్క విలువల మొత్తాన్ని గణిస్తుంది. ఈ ఫంక్షన్ తప్పనిసరిగా సంఖ్యాపరంగా ఒక వాదనను తీసుకుంటుంది. కింది SQL స్టేట్మెంట్ పూర్ణాంక విలువలను కలిగి ఉన్న “పుస్తకాలు” పట్టిక యొక్క ధర ఫీల్డ్లోని అన్ని విలువల మొత్తాన్ని గణిస్తుంది.
ఎంచుకోండి మొత్తం ( ధర ) AS `మొత్తం పుస్తకం ధర`నుండి పుస్తకాలు;
అవుట్పుట్ 'పుస్తకాలు' పట్టిక యొక్క ధర ఫీల్డ్ యొక్క అన్ని విలువల సమ్మషన్ విలువను చూపుతుంది. ధర ఫీల్డ్ యొక్క నాలుగు విలువలు 39, 49, 35 మరియు 45. ఈ విలువల మొత్తం 168.
నిర్దిష్ట ఫీల్డ్ యొక్క గరిష్ట మరియు కనిష్ట విలువలను కనుగొనండి
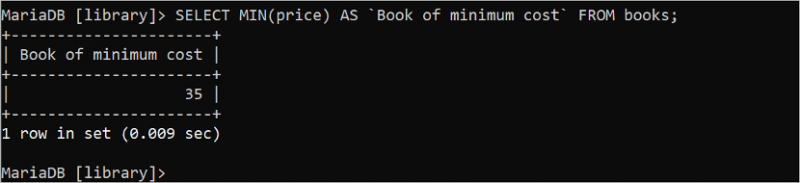
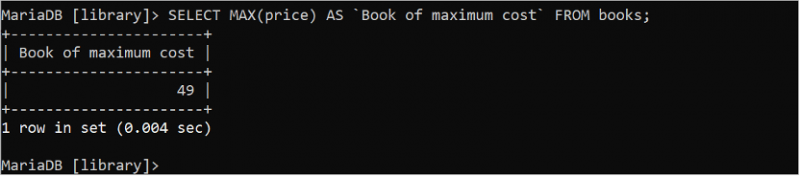
MIN() మరియు MAX() మొత్తం ఫంక్షన్లు టేబుల్ యొక్క నిర్దిష్ట ఫీల్డ్ యొక్క కనిష్ట మరియు గరిష్ట విలువలను కనుగొనడానికి ఉపయోగించబడతాయి. రెండు విధులు తప్పనిసరిగా సంఖ్యాపరంగా ఒక వాదనను తీసుకుంటాయి. కింది SQL స్టేట్మెంట్ పూర్ణాంకం అయిన “పుస్తకాల” పట్టిక నుండి కనీస ధర విలువను కనుగొంటుంది.
ఎంచుకోండి MIN ( ధర ) AS `కనీస ధర పుస్తకం` నుండి పుస్తకాలు;ముప్పై ఐదు (35) అనేది అవుట్పుట్లో ముద్రించబడిన ధర ఫీల్డ్ యొక్క కనిష్ట విలువ.
కింది SQL స్టేట్మెంట్ 'పుస్తకాలు' పట్టిక నుండి గరిష్ట ధర విలువను కనుగొంటుంది:
ఎంచుకోండి గరిష్టంగా ( ధర ) AS `గరిష్ట ధర పుస్తకం` నుండి పుస్తకాలు;నలభై తొమ్మిది (49) అనేది అవుట్పుట్లో ముద్రించబడిన ధర ఫీల్డ్ యొక్క గరిష్ట విలువ.
డేటా లేదా ఫీల్డ్ యొక్క నిర్దిష్ట భాగాన్ని చదవండి
స్ట్రింగ్ డేటా యొక్క నిర్దిష్ట భాగాన్ని లేదా టేబుల్ యొక్క నిర్దిష్ట ఫీల్డ్ విలువను తిరిగి పొందడానికి SQL స్టేట్మెంట్లో SUBSTR() ఫంక్షన్ ఉపయోగించబడుతుంది. ఈ ఫంక్షన్ మూడు వాదనలను కలిగి ఉంది. మొదటి ఆర్గ్యుమెంట్ స్ట్రింగ్ విలువ లేదా స్ట్రింగ్ అయిన టేబుల్ యొక్క ఫీల్డ్ విలువను కలిగి ఉంటుంది. రెండవ ఆర్గ్యుమెంట్ మొదటి ఆర్గ్యుమెంట్ నుండి తిరిగి పొందబడిన ఉప-స్ట్రింగ్ యొక్క ప్రారంభ స్థానాన్ని కలిగి ఉంటుంది మరియు ఈ విలువ యొక్క లెక్కింపు 1 నుండి ప్రారంభమవుతుంది. మూడవ ఆర్గ్యుమెంట్ ప్రారంభ స్థానం నుండి లెక్కించడం ప్రారంభించే ఉప-స్ట్రింగ్ యొక్క పొడవును కలిగి ఉంటుంది.
కింది SELECT స్టేట్మెంట్ 'లెర్న్ SQL బేసిక్స్' స్ట్రింగ్ నుండి మొదటి ఐదు అక్షరాలను కత్తిరించి ప్రింట్ చేస్తుంది, ఇక్కడ ప్రారంభ స్థానం 1 మరియు పొడవు 5:
ఎంచుకోండి SUBSTR ( 'SQL బేసిక్స్ నేర్చుకోండి' , 1 , 5 ) AS `సబ్స్ట్రింగ్ విలువ` ;“లెర్న్ SQL బేసిక్స్” స్ట్రింగ్లోని మొదటి ఐదు అక్షరాలు అవుట్పుట్లో ప్రింట్ చేయబడిన “లెర్న్”.
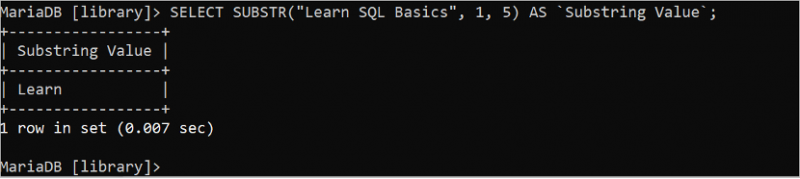
కింది SELECT స్టేట్మెంట్ ప్రారంభ స్థానం 7 మరియు పొడవు 3 ఉన్న “SQL బేసిక్స్ నేర్చుకోండి” స్ట్రింగ్ నుండి SQLని కట్ చేసి ప్రింట్ చేస్తుంది:
ఎంచుకోండి SUBSTR ( 'SQL బేసిక్స్ నేర్చుకోండి' , 7 , 3 ) AS `సబ్స్ట్రింగ్ విలువ` ;మునుపటి ప్రశ్నను అమలు చేసిన తర్వాత క్రింది అవుట్పుట్ కనిపిస్తుంది:

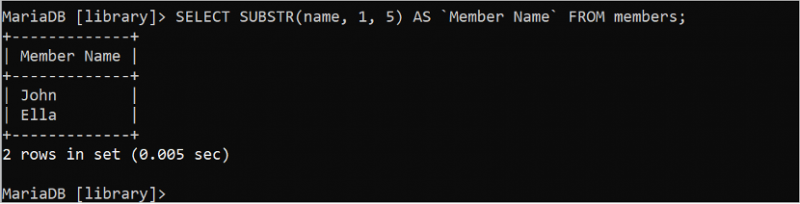
కింది SELECT స్టేట్మెంట్ 'సభ్యులు' పట్టిక యొక్క పేరు ఫీల్డ్ నుండి మొదటి ఐదు అక్షరాలను కత్తిరించి ముద్రిస్తుంది:
ఎంచుకోండి SUBSTR ( పేరు , 1 , 5 ) AS `సభ్యుని పేరు` నుండి సభ్యులు;అవుట్పుట్ 'సభ్యులు' పట్టిక యొక్క పేరు ఫీల్డ్ యొక్క ప్రతి విలువ యొక్క మొదటి ఐదు అక్షరాలను చూపుతుంది.
సంగ్రహణ తర్వాత టేబుల్ డేటాను చదవండి
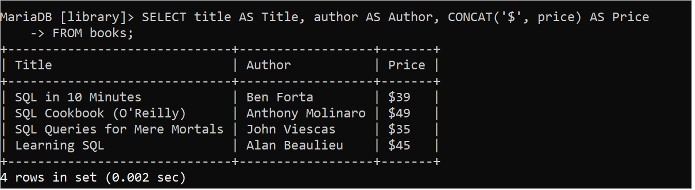
CONCAT() ఫంక్షన్ టేబుల్ యొక్క ఒకటి లేదా అంతకంటే ఎక్కువ ఫీల్డ్లను కలపడం ద్వారా లేదా స్ట్రింగ్ డేటా లేదా టేబుల్ యొక్క నిర్దిష్ట ఫీల్డ్ విలువను జోడించడం ద్వారా అవుట్పుట్ను రూపొందించడానికి ఉపయోగించబడుతుంది. కింది SQL స్టేట్మెంట్ “పుస్తకాల” పట్టిక యొక్క శీర్షిక, రచయిత మరియు ధర ఫీల్డ్ల విలువలను చదువుతుంది మరియు CONCAT() ఫంక్షన్ని ఉపయోగించి ధర ఫీల్డ్లోని ప్రతి విలువతో “$” స్ట్రింగ్ విలువ జోడించబడుతుంది.
ఎంచుకోండి శీర్షిక AS శీర్షిక , రచయిత AS రచయిత , CONCAT ( '$' , ధర ) AS ధరనుండి పుస్తకాలు;
ధర ఫీల్డ్ యొక్క విలువలు '$' స్ట్రింగ్తో కలపడం ద్వారా అవుట్పుట్లో ముద్రించబడతాయి.
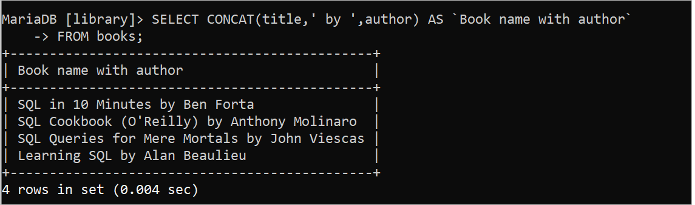
CONCAT() ఫంక్షన్ని ఉపయోగించి 'బుక్స్' టేబుల్ యొక్క శీర్షిక మరియు రచయిత ఫీల్డ్ల విలువలను 'ద్వారా' స్ట్రింగ్ విలువతో కలపడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి:
ఎంచుకోండి CONCAT ( శీర్షిక , 'ద్వారా' , రచయిత ) AS `రచయితతో పుస్తకం పేరు`నుండి పుస్తకాలు;
మునుపటి SELECT ప్రశ్నను అమలు చేసిన తర్వాత క్రింది అవుట్పుట్ కనిపిస్తుంది:
గణిత గణన తర్వాత టేబుల్ డేటాను చదవండి
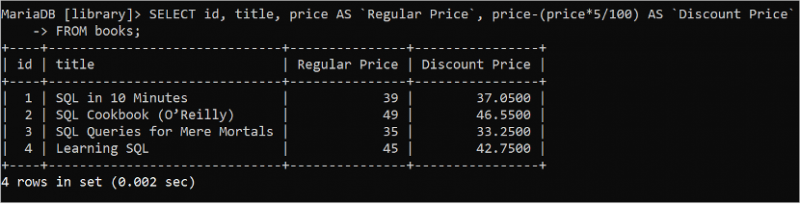
SELECT స్టేట్మెంట్ని ఉపయోగించి పట్టిక విలువలను తిరిగి పొందే సమయంలో ఏదైనా గణిత గణన చేయవచ్చు. 5% తగ్గింపును లెక్కించిన తర్వాత id, టైటిల్, ధర మరియు తగ్గింపు ధర విలువను చదవడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి.
ఎంచుకోండి id , శీర్షిక , ధర AS `సాధారణ ధర` , ధర - ( ధర * 5 / 100 ) AS `తగ్గింపు ధర`నుండి పుస్తకాలు;
కింది అవుట్పుట్ ప్రతి పుస్తకం యొక్క సాధారణ ధర మరియు తగ్గింపు ధరను చూపుతుంది:
పట్టిక యొక్క వీక్షణను సృష్టించండి
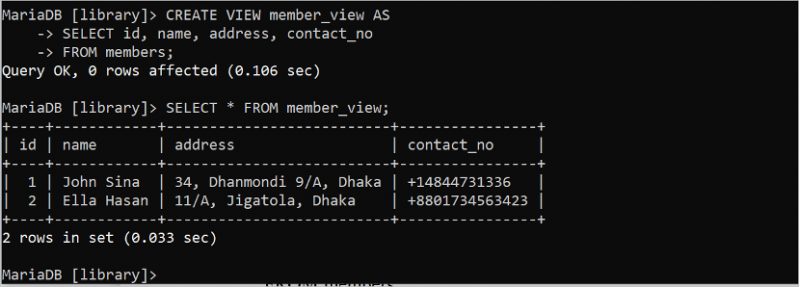
ప్రశ్నను సులభతరం చేయడానికి VIEW ఉపయోగించబడుతుంది మరియు డేటాబేస్కు అదనపు భద్రతను అందిస్తుంది. ఇది ఒకటి లేదా అంతకంటే ఎక్కువ పట్టికల నుండి రూపొందించబడిన వర్చువల్ పట్టిక వలె పనిచేస్తుంది. 'సభ్యుల' పట్టిక ఆధారంగా ఒక సాధారణ వీక్షణను సృష్టించడం మరియు అమలు చేయడం యొక్క పద్ధతి క్రింది ఉదాహరణలో చూపబడింది. SELECT స్టేట్మెంట్ ఉపయోగించి వీక్షణ అమలు చేయబడుతుంది. కింది SQL స్టేట్మెంట్ id, పేరు, చిరునామా మరియు కాంటాక్ట్_నో ఫీల్డ్లతో “సభ్యుల” పట్టిక యొక్క వీక్షణను సృష్టిస్తుంది. SELECT స్టేట్మెంట్ మెంబర్_వ్యూని అమలు చేస్తుంది.
సృష్టించు వీక్షణ సభ్యుడు_వ్యూ ASఎంచుకోండి id , పేరు , చిరునామా , సంప్రదంచాల్సిన నెం
నుండి సభ్యులు;
ఎంచుకోండి * నుండి సభ్యుడు_వ్యూ;
వీక్షణను సృష్టించి మరియు అమలు చేసిన తర్వాత క్రింది అవుట్పుట్ కనిపిస్తుంది:
నిర్దిష్ట పరిస్థితి ఆధారంగా పట్టికను నవీకరించండి
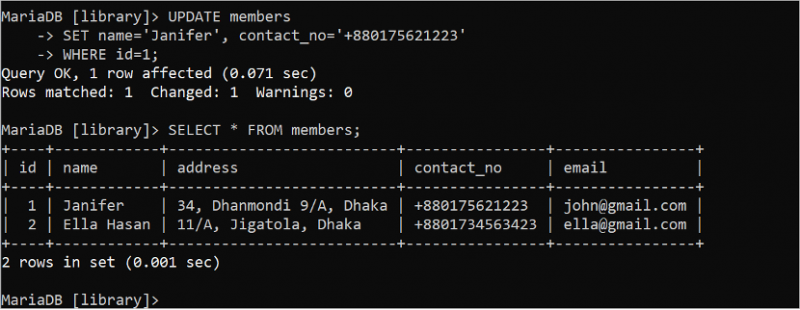
పట్టికలోని కంటెంట్ను నవీకరించడానికి UPDATE స్టేట్మెంట్ ఉపయోగించబడుతుంది. ఏదైనా అప్డేట్ ప్రశ్న WHERE నిబంధన లేకుండా అమలు చేయబడితే, UPDATE ప్రశ్నలో ఉపయోగించిన అన్ని ఫీల్డ్లు నవీకరించబడతాయి. కాబట్టి, సరైన WHERE నిబంధనతో UPDATE స్టేట్మెంట్ను ఉపయోగించడం అవసరం. id ఫీల్డ్ విలువ 1 అయిన పేరు మరియు contact_no ఫీల్డ్లను అప్డేట్ చేయడానికి క్రింది UPDATE స్టేట్మెంట్ను అమలు చేయండి. తర్వాత, డేటా సరిగ్గా అప్డేట్ చేయబడిందో లేదో తనిఖీ చేయడానికి SELECT స్టేట్మెంట్ను అమలు చేయండి.
నవీకరణ సభ్యులుసెట్ పేరు = 'జానిఫర్' , సంప్రదంచాల్సిన నెం = '+880175621223'
ఎక్కడ id = 1 ;
ఎంచుకోండి * నుండి సభ్యులు;
అప్డేట్ స్టేట్మెంట్ విజయవంతంగా అమలు చేయబడిందని క్రింది అవుట్పుట్ చూపిస్తుంది. పేరు ఫీల్డ్ యొక్క విలువ 'Janifer'కి మార్చబడింది మరియు UPDATE ప్రశ్నను ఉపయోగించి 1 యొక్క id విలువను కలిగి ఉన్న రికార్డ్ యొక్క contact_no ఫీల్డ్ '+880175621223'కి మార్చబడింది:
నిర్దిష్ట పరిస్థితి ఆధారంగా టేబుల్ డేటాను తొలగించండి
నిర్దిష్ట కంటెంట్ లేదా పట్టికలోని మొత్తం కంటెంట్ను తొలగించడానికి DELETE స్టేట్మెంట్ ఉపయోగించబడుతుంది. WHERE నిబంధన లేకుండా ఏదైనా DELETE ప్రశ్న అమలు చేయబడితే, అన్ని ఫీల్డ్లు తొలగించబడతాయి. కాబట్టి, సరైన WHERE నిబంధనతో UPDATE స్టేట్మెంట్ను ఉపయోగించడం అవసరం. ID విలువ 4 ఉన్న పుస్తకాల పట్టిక నుండి మొత్తం డేటాను తొలగించడానికి క్రింది DELETE స్టేట్మెంట్ను అమలు చేయండి. తర్వాత, డేటా సరిగ్గా తొలగించబడిందో లేదో తనిఖీ చేయడానికి SELECT స్టేట్మెంట్ను అమలు చేయండి.
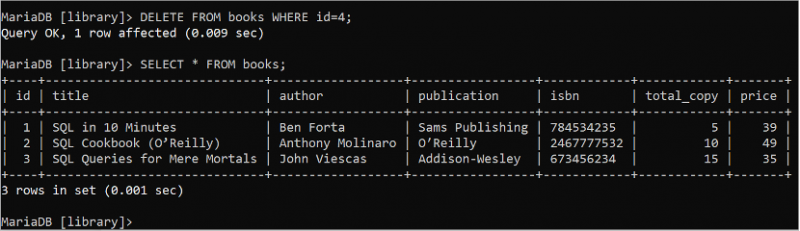
తొలగించు నుండి పుస్తకాలు ఎక్కడ id = 4 ;ఎంచుకోండి * నుండి పుస్తకాలు;
కింది అవుట్పుట్ DELETE స్టేట్మెంట్ విజయవంతంగా అమలు చేయబడిందని చూపిస్తుంది. ది 4 వ DELETE ప్రశ్నను ఉపయోగించి పుస్తకాల పట్టిక రికార్డు తీసివేయబడుతుంది:
పట్టిక నుండి అన్ని రికార్డులను తొలగించండి
'పుస్తకాలు' పట్టిక నుండి అన్ని రికార్డ్లను తొలగించడానికి కింది DELETE స్టేట్మెంట్ను అమలు చేయండి, ఇక్కడ నిబంధన ఎక్కడ విస్మరించబడింది. తర్వాత, టేబుల్ కంటెంట్ని తనిఖీ చేయడానికి SELECT ప్రశ్నను అమలు చేయండి.
తొలగించు నుండి పుస్తకం_అరువు_సమాచారం;ఎంచుకోండి * నుండి పుస్తకం_అరువు_సమాచారం;
DELETE ప్రశ్నను అమలు చేసిన తర్వాత “పుస్తకాలు” పట్టిక ఖాళీగా ఉందని క్రింది అవుట్పుట్ చూపిస్తుంది:

ఏదైనా పట్టిక స్వీయ-పెంపు లక్షణాన్ని కలిగి ఉంటే మరియు పట్టిక నుండి అన్ని రికార్డ్లు తొలగించబడితే, పట్టికను ఖాళీ చేసిన తర్వాత కొత్త రికార్డ్ను చొప్పించినప్పుడు ఆటో-ఇంక్రిమెంట్ ఫీల్డ్ చివరి ఇంక్రిమెంట్ నుండి లెక్కించడం ప్రారంభమవుతుంది. TRUNCATE ప్రకటనను ఉపయోగించి ఈ సమస్యను పరిష్కరించవచ్చు. ఇది పట్టిక నుండి అన్ని రికార్డ్లను తొలగించడానికి కూడా ఉపయోగించబడుతుంది, అయితే పట్టిక నుండి అన్ని రికార్డ్లను తొలగించిన తర్వాత ఆటో-ఇంక్రిమెంట్ ఫీల్డ్ 1 నుండి లెక్కింపు ప్రారంభమవుతుంది. TRUNCATE స్టేట్మెంట్ యొక్క SQL కింది వాటిలో చూపబడింది:
కత్తిరించు పుస్తకం_అరువు_సమాచారం;పట్టికను వదలండి
ఒకటి లేదా అంతకంటే ఎక్కువ పట్టికలను తనిఖీ చేయడం ద్వారా లేదా పట్టిక ఉనికిలో ఉందో లేదో తనిఖీ చేయకుండా వదిలివేయవచ్చు. క్రింది DROP స్టేట్మెంట్లు “book_borrow_info” పట్టికను తొలగిస్తాయి మరియు “SHOW పట్టికలు” స్టేట్మెంట్ సర్వర్లో టేబుల్ ఉందో లేదో తనిఖీ చేస్తుంది.
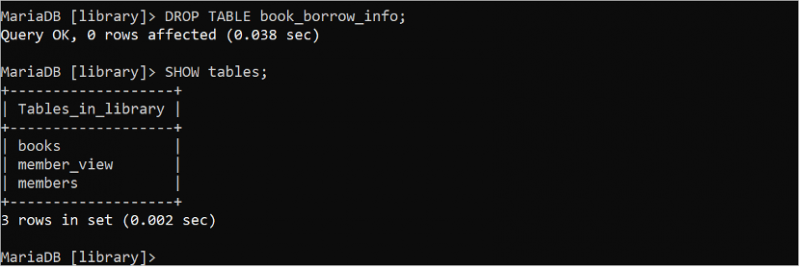
డ్రాప్ చేయండి పట్టిక పుస్తకం_అరువు_సమాచారం;చూపించు పట్టికలు ;
“book_borrow_info” పట్టిక పడిపోయినట్లు అవుట్పుట్ చూపిస్తుంది.
టేబుల్ సర్వర్లో ఉందా లేదా అని తనిఖీ చేసిన తర్వాత దానిని వదిలివేయవచ్చు. ఈ పట్టికలు సర్వర్లో ఉంటే పుస్తకాలు మరియు సభ్యుల పట్టికను తొలగించడానికి క్రింది DROP స్టేట్మెంట్ను అమలు చేయండి. తర్వాత, 'షో టేబుల్స్' స్టేట్మెంట్ సర్వర్లో టేబుల్లు ఉన్నాయో లేదో తనిఖీ చేస్తుంది.
డ్రాప్ చేయండి పట్టిక IF ఉనికిలో ఉంది పుస్తకాలు , సభ్యులు;చూపించు పట్టికలు ;
పట్టికలు సర్వర్ నుండి తొలగించబడినట్లు క్రింది అవుట్పుట్ చూపిస్తుంది:

డేటాబేస్ను వదలండి
సర్వర్ నుండి 'లైబ్రరీ' డేటాబేస్ను తొలగించడానికి క్రింది SQL స్టేట్మెంట్ను అమలు చేయండి:
డ్రాప్ చేయండి డేటాబేస్ గ్రంధాలయం;అవుట్పుట్ డేటాబేస్ పడిపోయినట్లు చూపిస్తుంది.

ముగింపు
MariaDB సర్వర్ యొక్క డేటాబేస్ను సృష్టించడానికి, యాక్సెస్ చేయడానికి, సవరించడానికి మరియు తొలగించడానికి ఎక్కువగా ఉపయోగించే SQL ప్రశ్న ఉదాహరణలు డేటాబేస్ మరియు మూడు పట్టికలను సృష్టించడం ద్వారా ఈ ట్యుటోరియల్లో చూపబడ్డాయి. కొత్త డేటాబేస్ యూజర్కి SQL బేసిక్స్ని సరిగ్గా నేర్చుకునేందుకు సహాయం చేయడానికి వివిధ SQL స్టేట్మెంట్ల ఉపయోగాలు చాలా సులభమైన ఉదాహరణలతో వివరించబడ్డాయి. సంక్లిష్ట ప్రశ్నల ఉపయోగాలు ఇక్కడ విస్మరించబడ్డాయి. కొత్త డేటాబేస్ వినియోగదారులు ఈ ట్యుటోరియల్ని సరిగ్గా చదివిన తర్వాత ఏదైనా డేటాబేస్తో పని చేయడం ప్రారంభించగలరు.