ఈ వ్యాసంలో, మేము దాని ప్రాముఖ్యతను విశ్లేషిస్తాము డేటా నిర్మాణాలు , వివిధ రకాలు డేటా నిర్మాణాలు C++లో అందుబాటులో ఉంది మరియు వాటిని మీ ప్రోగ్రామ్లలో ఎలా సమర్థవంతంగా ఉపయోగించాలి.
C++లో డేటా స్ట్రక్చర్ అంటే ఏమిటి
ది డేటా నిర్మాణం ప్రోగ్రామింగ్లో ముఖ్యమైన భావన మరియు డేటాను నిల్వ చేయడం మరియు నిర్వహించడంలో కీలక పాత్ర పోషిస్తుంది. C++లో, డేటా స్ట్రక్చర్ అనేది డేటాను నిల్వ చేయడానికి మరియు నిర్దిష్ట ఆకృతిలో డేటాను నిర్వహించడానికి ఒక మార్గంగా నిర్వచించబడుతుంది. ఇది డేటాను సమర్థవంతంగా యాక్సెస్ చేయడానికి మరియు తారుమారు చేయడానికి అనుమతిస్తుంది, ప్రోగ్రామర్లు కోడ్ని వ్రాయడం మరియు నిర్వహించడం సులభతరం చేస్తుంది.
C++లో, ది డేటా నిర్మాణాలు కింది వాక్యనిర్మాణాన్ని కలిగి ఉండండి:
నిర్మాణం నిర్మాణం_పేరు {
డేటాటైప్1 పేరు1 ;
డేటాటైప్2 పేరు2 ;
డేటాటైప్3 పేరు3 ;
డేటాటైప్4 పేరు4 ;
..
..
..
} obj_పేరు ;
పై వాక్యనిర్మాణంలో, ది struct కీవర్డ్ నిర్మాణాన్ని నిర్వచించడానికి ఉపయోగించబడుతుంది మరియు నిర్మాణం_పేరు నిర్మాణం యొక్క వినియోగదారు నిర్వచించిన పేరు మరియు ఇది మారవచ్చు. ది డేటాటైప్1 నిర్మాణం యొక్క సభ్యుని యొక్క డేటా రకం మరియు పేరు1 నిర్మాణం యొక్క సభ్యుని పేరు మరియు obj_పేరు నిర్మాణం నిర్వచించబడిన వస్తువు పేరు.
ఉదాహరణ
దిగువ ఉదాహరణలో, ది నిర్మాణం సమాచారం ముగ్గురు సభ్యులను కలిగి ఉంటుంది: పేరు, వయస్సు, మరియు పౌరసత్వం.
నిర్మాణం సమాచారం
{
చార్ పేరు [ యాభై ] ;
int పౌరసత్వం ;
int వయస్సు ;
}
ఈ కోడ్ని C++లో అమలు చేద్దాం, మేము ఈ సభ్యులందరినీ నిర్మాణ వ్యక్తిలో నిర్వచించాము మరియు ఏ స్థలాన్ని కేటాయించలేదు. ప్రధాన విధిలో, మేము ఈ సభ్యులను నిర్దిష్ట విలువలతో ప్రారంభించాము మరియు వాటిని ముద్రించాము:
#నేమ్స్పేస్ stdని ఉపయోగిస్తోంది ;
నిర్మాణం సమాచారం
{
స్ట్రింగ్ పేరు ;
int వయస్సు ;
} ;
int ప్రధాన ( శూన్యం ) {
నిర్మాణం సమాచారం p ;
p. పేరు = 'జైనాబ్' ;
p. వయస్సు = 23 ;
కోట్ << 'వ్యక్తి పేరు:' << p. పేరు << endl ;
కోట్ << 'వ్యక్తి వయస్సు:' << p. వయస్సు << endl ;
తిరిగి 0 ;
}
కోడ్ పేరు పెట్టబడిన నిర్మాణాన్ని నిర్వచిస్తుంది సమాచారం రెండు లక్షణాలతో: పేరు మరియు వయస్సు. ప్రధాన ఫంక్షన్లో, కొత్తది సమాచారం వస్తువు సృష్టించబడింది మరియు దాని పేరు మరియు వయస్సు కేటాయించబడతాయి. చివరగా, ఈ ఫీల్డ్ల విలువలు కౌట్ ఉపయోగించి కన్సోల్కు ముద్రించబడతాయి.
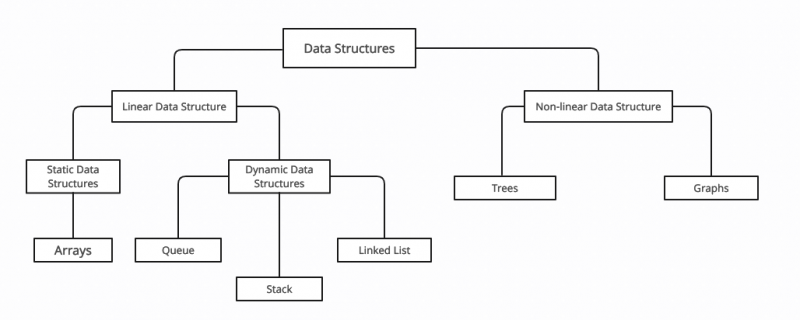
C++లో డేటా స్ట్రక్చర్ వర్గీకరణ
C++ లో డేటా నిర్మాణం రెండు విస్తృత వర్గాలుగా విభజించబడింది: లీనియర్ మరియు నాన్ లీనియర్ డేటా స్ట్రక్చర్స్ . డేటా నిర్మాణాలు క్రింది లక్షణాల ఆధారంగా విభజించబడ్డాయి:
| లక్షణం | వివరణ | ఉదాహరణ |
| లీనియర్ | డేటా లీనియర్ సీక్వెన్స్లో అమర్చబడింది | శ్రేణులు |
| నాన్-లీనియర్ | డేటాలోని అంశాలు లీనియర్ సీక్వెన్స్లో లేవు | గ్రాఫ్, చెట్టు |
| స్థిరమైన | స్థానం, పరిమాణం మరియు మెమరీ పరిష్కరించబడ్డాయి | శ్రేణులు |
| డైనమిక్ | ప్రోగ్రామ్ యొక్క అమలుపై ఆధారపడి పరిమాణం మారుతుంది | లింక్ చేయబడిన జాబితా |
| సజాతీయమైనది | వస్తువులు ఒకే రకమైనవి | శ్రేణులు |
| సజాతీయం కానిది | అంశాలు ఒకే రకమైనవి కావచ్చు లేదా కాకపోవచ్చు | నిర్మాణాలు |
C++లోని డేటా స్ట్రక్చర్ల వర్గాలు:
1: శ్రేణులు
శ్రేణులు C++ యొక్క అత్యంత ప్రాథమిక డేటా నిర్మాణాలు. శ్రేణి అనేది ఒకే రకమైన డేటాతో కూడిన మూలకాల సమూహం. శ్రేణులు మొత్తం డేటా సెట్లో కార్యకలాపాలను సులభతరం చేస్తాయి. శ్రేణులలో నిల్వ చేయబడిన విలువలు మూలకాలుగా పిలువబడతాయి.
2: లింక్డ్ లిస్ట్
లింక్డ్ లిస్ట్లోని డేటా మూలకాలు నోడ్ల ద్వారా కనెక్ట్ చేయబడ్డాయి. ప్రతి నోడ్ దాని తర్వాత నోడ్ యొక్క చిరునామా మరియు డేటాను కలిగి ఉంటుంది. నోడ్లను జోడించడానికి మరియు తొలగించడానికి అవి ఉత్తమమైనవి. లింక్డ్ లిస్ట్లు రెండు రకాలను కలిగి ఉంటాయి ఒకటి సింగిల్ మరియు మరొకటి రెట్టింపు లింక్డ్ జాబితాలు. ఒకే లింక్ చేయబడిన జాబితాలో, మునుపటి నోడ్ దాని తర్వాత నోడ్ యొక్క డేటాను కలిగి ఉంటుంది కానీ తదుపరి నోడ్ మునుపటి నోడ్ గురించి తెలియదు. రెట్టింపు లింక్ చేయబడిన జాబితాలో, దిశ ముందుకు మరియు వెనుకకు ఉంది.
3: స్టాక్లు
స్టాక్లు అనేది LIFO (లాస్ట్ ఇన్ ఫస్ట్ అవుట్) సూత్రాన్ని అనుసరించే నైరూప్య డేటా రకం. ఈ నియమం అంటే చివరగా చొప్పించిన మూలకం ముందుగా తొలగించబడుతుంది. అవి రికర్సివ్ బ్యాక్ట్రాకింగ్ అల్గారిథమ్లతో ఉపయోగించబడతాయి.
4: తోకలు
క్యూలు కూడా వియుక్త డేటా రకం మరియు FIFO (ఫస్ట్ ఇన్ మరియు ఫస్ట్ అవుట్) నియమాన్ని అనుసరిస్తాయి. ఈ నియమం అంటే ముందుగా చొప్పించిన మూలకం ముందుగా తొలగించబడుతుంది. నిజ-సమయ సిస్టమ్ వివరణలను నిర్వహించేటప్పుడు అవి సహాయపడతాయి.
5: చెట్లు
చెట్లు బహుళ నోడ్లతో కూడిన నాన్లీనియర్ డేటా స్ట్రక్చర్ల సమితి. ఇది రెండు శీర్షాలతో ఒక అంచుని మాత్రమే అనుమతిస్తుంది.
6: గ్రాఫ్లు
గ్రాఫ్లో, ప్రతి నోడ్ ఒక శీర్షం మరియు ప్రతి శీర్షం అంచు ద్వారా మరొక శీర్షానికి అనుసంధానించబడి ఉంటుంది. గోళాలు శీర్షం మరియు బాణాలు అంచులు, అవి నిజ జీవిత దృశ్యాలు లేదా నాడీ నెట్వర్క్లను అమలు చేయడానికి ఉపయోగించబడతాయి. గ్రాఫ్లు మూడు విభిన్న రకాలను కలిగి ఉంటాయి: మళ్లించని గ్రాఫ్, ద్వి-దర్శక గ్రాఫ్ మరియు వెయిటెడ్ గ్రాఫ్.
డేటా నిర్మాణాలపై కార్యకలాపాలు నిర్వహిస్తాయి
మేము C++లో డేటా స్ట్రక్చర్లపై కింది విధులను నిర్వహించగలము:
- డేటా స్ట్రక్చర్లలో కొత్త డేటా ఎలిమెంట్ల చొప్పించడం.
- డేటా నిర్మాణం నుండి ఇప్పటికే ఉన్న డేటా మూలకాల తొలగింపు.
- డేటా నిర్మాణంలో అన్ని డేటా మూలకాలను ప్రదర్శించండి.
- డేటా నిర్మాణంలో నిర్దిష్ట మూలకం కోసం శోధించండి.
- అన్ని మూలకాలను ఆరోహణ లేదా అవరోహణ క్రమంలో అమర్చండి.
- రెండు డేటా స్ట్రక్చర్ల నుండి ఎలిమెంట్లను కలపండి మరియు కొత్తదాన్ని సృష్టించండి.
క్రింది గీత
C++లోని డేటా స్ట్రక్చర్లు డేటాను సమర్ధవంతంగా నిర్వహించే మార్గం కాబట్టి దానిని యాక్సెస్ చేయవచ్చు. మీ ప్రాజెక్ట్ కోసం తగిన డేటా నిర్మాణాన్ని ఎంచుకోవడం చాలా ముఖ్యం, మీరు డేటాను వరుసగా జోడించాలనుకుంటే శ్రేణుల కోసం వెళ్లండి. డేటా స్ట్రక్చర్ కాన్సెప్ట్ను అర్థం చేసుకోవడం ప్రోగ్రామింగ్ మరియు అల్గారిథమ్ డిజైన్లో నైపుణ్యం సాధించడంలో మీకు సహాయపడుతుంది.