C#లో XMLని చదవడం
C#లో XML ఫైల్ని చదవడానికి అనేక మార్గాలు ఉన్నాయి మరియు ప్రతి పద్ధతికి దాని ప్రయోజనాలు మరియు అప్రయోజనాలు ఉన్నాయి మరియు ఎంపిక ప్రాజెక్ట్ యొక్క అవసరాలపై ఆధారపడి ఉంటుంది. C#లో XML ఫైల్ని చదవడానికి క్రింద కొన్ని మార్గాలు ఉన్నాయి:
- XmlDocumentని ఉపయోగించడం
- XDocumentని ఉపయోగించడం
- XmlReaderని ఉపయోగించడం
- Xml నుండి LINQని ఉపయోగించడం
- XPath ఉపయోగించి
నేను సృష్టించిన XML ఫైల్ యొక్క కంటెంట్ ఇక్కడ ఉంది మరియు రాబోయే పద్ధతులలో ప్రదర్శన కోసం ఉపయోగించబడుతుంది:
< ?xml సంస్కరణ: Telugu = '1.0' ఎన్కోడింగ్ = 'utf-8' ? >
< ఉద్యోగులు >
< ఉద్యోగి >
< id > 1 id >
< పేరు > సామ్ బోష్ పేరు >
< శాఖ > మార్కెటింగ్ శాఖ >
< జీతం > 50000 జీతం >
ఉద్యోగి >
< ఉద్యోగి >
< id > 2 id >
< పేరు > జేన్ డో పేరు >
< శాఖ > ఫైనాన్స్ శాఖ >
< జీతం > 60000 జీతం >
ఉద్యోగి >
< ఉద్యోగి >
< id > 3 id >
< పేరు > జేమ్స్ పేరు >
< శాఖ > మానవ వనరులు శాఖ >
< జీతం > 70000 జీతం >
ఉద్యోగి >
ఉద్యోగులు >
1: XmlDocumentని ఉపయోగించడం
C#లో XML ఫైల్ను చదవడానికి, మీరు XmlDocument తరగతి లేదా XDocument తరగతిని ఉపయోగించవచ్చు, రెండూ System.Xml నేమ్స్పేస్లో భాగమే. XmlDocument క్లాస్ XMLని చదవడానికి DOM (డాక్యుమెంట్ ఆబ్జెక్ట్ మోడల్) విధానాన్ని అందిస్తుంది, అయితే XDocument క్లాస్ LINQ (భాష-ఇంటిగ్రేటెడ్ క్వెరీ) విధానాన్ని అందిస్తుంది. XML ఫైల్ను చదవడానికి XmlDocument తరగతిని ఉపయోగించే ఉదాహరణ ఇక్కడ ఉంది:
వ్యవస్థను ఉపయోగించడం;
System.Xmlని ఉపయోగించడం;
తరగతి కార్యక్రమం
{
స్టాటిక్ శూన్య ప్రధాన ( స్ట్రింగ్ [ ] ఆర్గ్స్ )
{
XmlDocument doc = కొత్త XmlDocument ( ) ;
doc.లోడ్ ( 'ఉద్యోగులు.xml' ) ;
XmlNodeList nodes = doc.DocumentElement.SelectNodes ( '/ఉద్యోగులు/ఉద్యోగి' ) ;
ప్రతి ( XmlNode నోడ్ లో నోడ్స్ )
{
స్ట్రింగ్ id = నోడ్.SelectSingleNode ( 'id' ) .InnerText;
string name = node.SelectSingleNode ( 'పేరు' ) .InnerText;
string Department = node.SelectSingleNode ( 'విభాగం' ) .InnerText;
స్ట్రింగ్ జీతం = నోడ్.SelectSingleNode ( 'జీతం' ) .InnerText;
కన్సోల్.WriteLine ( 'ID: {0}, పేరు: {1}, విభాగం: {2}, జీతం: {3}' , id , పేరు, విభాగం, జీతం ) ;
}
}
}
ఈ కోడ్ XML ఫైల్ను లోడ్ చేయడానికి XmlDocument తరగతిని మరియు ఉద్యోగి నోడ్ల జాబితాను తిరిగి పొందడానికి SelectNodes పద్ధతిని ఉపయోగిస్తుంది. ఆపై, ప్రతి ఉద్యోగి నోడ్ కోసం, ఇది id, పేరు, విభాగం మరియు జీతం చైల్డ్ నోడ్ల విలువలను తిరిగి పొందడానికి SelectSingleNode పద్ధతిని ఉపయోగిస్తుంది మరియు వాటిని Console.WriteLine ఉపయోగించి ప్రదర్శిస్తుంది:

2: XDocumentని ఉపయోగించడం
ప్రత్యామ్నాయంగా, మీరు LINQ విధానాన్ని ఉపయోగించి XML ఫైల్ని చదవడానికి XDocument తరగతిని కూడా ఉపయోగించవచ్చు మరియు దీన్ని ఎలా చేయాలో వివరించే కోడ్ క్రింద ఉంది:
వ్యవస్థను ఉపయోగించడం;తరగతి కార్యక్రమం
{
స్టాటిక్ శూన్య ప్రధాన ( స్ట్రింగ్ [ ] ఆర్గ్స్ )
{
XDocument doc = XDocument.Load ( 'ఉద్యోగులు.xml' ) ;
ప్రతి ( XElement మూలకం లో doc.వారసులు ( 'ఉద్యోగి' ) )
{
int id = అంతర్భాగము ( మూలకం.మూలకం ( 'id' ) .విలువ ) ;
string name = మూలకం.మూలకం ( 'పేరు' ) .విలువ;
string Department = మూలకం.మూలకం ( 'విభాగం' ) .విలువ;
int salary = int.అవలోకనం ( మూలకం.మూలకం ( 'జీతం' ) .విలువ ) ;
కన్సోల్.WriteLine ( $ 'ID: {id}, పేరు: {name}, విభాగం: {department}, జీతం: {salary}' ) ;
}
}
}
XML ఫైల్ XDocument.Load పద్ధతిని ఉపయోగించి XDocument ఆబ్జెక్ట్లోకి లోడ్ చేయబడింది. XML ఫైల్ యొక్క 'ఉద్యోగి' మూలకాలు అన్ని డిసెండెంట్స్ టెక్నిక్ ఉపయోగించి తిరిగి పొందబడతాయి. ప్రతి మూలకం కోసం, దాని చైల్డ్ ఎలిమెంట్లు ఎలిమెంట్ పద్ధతిని ఉపయోగించి యాక్సెస్ చేయబడతాయి మరియు వాటి విలువలు విలువ ప్రాపర్టీని ఉపయోగించి సంగ్రహించబడతాయి. చివరగా, సంగ్రహించిన డేటా కన్సోల్కు ముద్రించబడుతుంది.
XDocument System.Xml.Linq నేమ్స్పేస్కు చెందినదని గమనించండి, కాబట్టి మీరు మీ C# ఫైల్ ఎగువన కింది ఉపయోగించి స్టేట్మెంట్ను చేర్చాలి

3: XmlReaderని ఉపయోగించడం
XmlReader అనేది C#లో XML ఫైల్ను చదవడానికి వేగవంతమైన మరియు సమర్థవంతమైన మార్గం. ఇది ఫైల్ను సీక్వెన్షియల్గా రీడ్ చేస్తుంది, అంటే ఇది ఒక సమయంలో ఒక నోడ్ను మాత్రమే లోడ్ చేస్తుంది, మెమరీలో హ్యాండిల్ చేయడం కష్టంగా ఉండే పెద్ద XML ఫైల్లతో పని చేయడానికి ఇది అనువైనదిగా చేస్తుంది.
వ్యవస్థను ఉపయోగించడం;System.Xmlని ఉపయోగించడం;
తరగతి కార్యక్రమం
{
స్టాటిక్ శూన్య ప్రధాన ( స్ట్రింగ్ [ ] ఆర్గ్స్ )
{
ఉపయోగించి ( XmlReader రీడర్ = XmlReader.Create ( 'ఉద్యోగులు.xml' ) )
{
అయితే ( రీడర్.చదవండి ( ) )
{
ఉంటే ( reader.NodeType == XmlNodeType.Element && రీడర్.పేరు == 'ఉద్యోగి' )
{
కన్సోల్.WriteLine ( 'ID:' + reader.GetAtribute ( 'id' ) ) ;
రీడర్.ReadToDescendant ( 'పేరు' ) ;
కన్సోల్.WriteLine ( 'పేరు:' + reader.ReadElementContentAsString ( ) ) ;
రీడర్.ReadToNextSibling ( 'విభాగం' ) ;
కన్సోల్.WriteLine ( 'విభాగం:' + reader.ReadElementContentAsString ( ) ) ;
రీడర్.ReadToNextSibling ( 'జీతం' ) ;
కన్సోల్.WriteLine ( 'జీతం:' + reader.ReadElementContentAsString ( ) ) ;
}
}
}
}
}
ఈ ఉదాహరణలో, మేము XmlReaderని ఉపయోగిస్తాము. XmlReader యొక్క ఉదాహరణను సృష్టించడానికి మరియు XML ఫైల్ పాత్ను పారామీటర్గా పాస్ చేయడానికి ఒక పద్ధతిని సృష్టించండి. XmlReader యొక్క రీడ్ పద్ధతిని ఉపయోగించి నోడ్ ద్వారా XML ఫైల్ నోడ్ ద్వారా చదవడానికి మేము కాసేపు లూప్ని ఉపయోగిస్తాము.
లూప్ లోపల, మేము ముందుగా XmlReader యొక్క NodeType మరియు Name లక్షణాలను ఉపయోగించి ప్రస్తుత నోడ్ ఉద్యోగి మూలకం కాదా అని తనిఖీ చేస్తాము. అలా అయితే, id అట్రిబ్యూట్ విలువను తిరిగి పొందడానికి మేము GetAttribute పద్ధతిని ఉపయోగిస్తాము.
తర్వాత, మేము రీడర్ను ఉద్యోగి మూలకంలోని పేరు మూలకానికి తరలించడానికి ReadToDescendant పద్ధతిని ఉపయోగిస్తాము. పేరు మూలకం యొక్క విలువ అప్పుడు ReadElementContentAsString ఫంక్షన్ని ఉపయోగించడం ద్వారా పొందబడుతుంది.
అదేవిధంగా, మేము రీడర్ను తదుపరి తోబుట్టువుల మూలకానికి తరలించడానికి మరియు విభాగం మరియు జీతం మూలకాల విలువను పొందడానికి ReadToNextSibling పద్ధతిని ఉపయోగిస్తాము.
చివరగా, మేము XML ఫైల్ని చదివిన తర్వాత XmlReader ఆబ్జెక్ట్ సరిగ్గా పారవేయబడిందని నిర్ధారించుకోవడానికి బ్లాక్ని ఉపయోగిస్తాము:
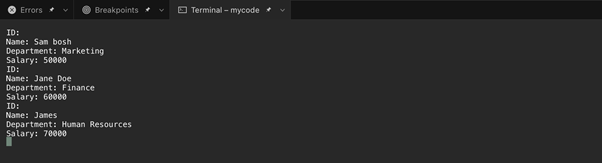
4: XML నుండి LINQ
C#లో LINQ నుండి XMLని ఉపయోగించి XML ఫైల్ని చదవడం అనేది XML డేటాను యాక్సెస్ చేయడానికి మరియు మానిప్యులేట్ చేయడానికి శక్తివంతమైన మార్గం. LINQ నుండి XML అనేది XML డేటాతో పని చేయడానికి సులభమైన మరియు సమర్థవంతమైన APIని అందించే LINQ సాంకేతికతలో ఒక భాగం.
వ్యవస్థను ఉపయోగించడం;System.Linqని ఉపయోగించడం;
System.Xml.Linqని ఉపయోగించడం;
తరగతి కార్యక్రమం
{
స్టాటిక్ శూన్య ప్రధాన ( స్ట్రింగ్ [ ] ఆర్గ్స్ )
{
XDocument doc = XDocument.Load ( 'ఉద్యోగులు.xml' ) ;
var ఉద్యోగులు = ఇ నుండి లో doc.వారసులు ( 'ఉద్యోగి' )
ఎంచుకోండి కొత్త
{
Id = ఇ.మూలకం ( 'id' ) .విలువ,
పేరు = ఇ.మూలకం ( 'పేరు' ) .విలువ,
శాఖ = ఇ.ఎలిమెంట్ ( 'విభాగం' ) .విలువ,
జీతం = ఇ.ఎలిమెంట్ ( 'జీతం' ) .విలువ
} ;
ప్రతి ( var ఉద్యోగి లో ఉద్యోగులు )
{
కన్సోల్.WriteLine ( $ 'Id: {employee.Id}, పేరు: {employee.Name}, విభాగం: {employee.Department}, జీతం: {employee.Salary}' ) ;
}
}
}
ఈ కోడ్లో, మేము ముందుగా XDocument.Load() పద్ధతిని ఉపయోగించి XML ఫైల్ను లోడ్ చేస్తాము. ఆపై, మేము XML డేటాను ప్రశ్నించడానికి LINQ నుండి XMLని ఉపయోగిస్తాము మరియు ప్రతి ఉద్యోగి మూలకం కోసం id, పేరు, విభాగం మరియు జీతం మూలకాలను ఎంచుకోండి. మేము ఈ డేటాను అనామక రకంలో నిల్వ చేసి, ఆపై కన్సోల్కు ఉద్యోగి సమాచారాన్ని ప్రింట్ చేయడానికి ఫలితాల ద్వారా లూప్ చేస్తాము.

5: XPathని ఉపయోగించడం
XPath అనేది నిర్దిష్ట అంశాలు, గుణాలు మరియు నోడ్లను గుర్తించడానికి XML డాక్యుమెంట్ ద్వారా నావిగేట్ చేయడానికి ఉపయోగించే ప్రశ్న భాష. ఇది XML డాక్యుమెంట్లో సమాచారాన్ని వెతకడానికి మరియు ఫిల్టర్ చేయడానికి సమర్థవంతమైన సాధనం. C#లో, XML ఫైల్ల నుండి డేటాను చదవడానికి మరియు సంగ్రహించడానికి మేము XPath భాషను ఉపయోగించవచ్చు.
వ్యవస్థను ఉపయోగించడం;System.Xml.XPath ఉపయోగించి;
System.Xmlని ఉపయోగించడం;
తరగతి కార్యక్రమం
{
స్టాటిక్ శూన్య ప్రధాన ( స్ట్రింగ్ [ ] ఆర్గ్స్ )
{
XmlDocument doc = కొత్త XmlDocument ( ) ;
doc.లోడ్ ( 'ఉద్యోగులు.xml' ) ;
// పత్రం నుండి XPathNavigatorని సృష్టించండి
XPathNavigator nav = doc.CreateNavigator ( ) ;
// XPath వ్యక్తీకరణను కంపైల్ చేయండి
XPathExpression exr = nav.సంకలనం ( '/ఉద్యోగులు/ఉద్యోగి/పేరు' ) ;
// వ్యక్తీకరణను అంచనా వేయండి మరియు ఫలితాల ద్వారా పునరావృతం చేయండి
XPathNodeIterator iterator = nav.Select ( exr ) ;
అయితే ( iterator.MoveNext ( ) )
{
కన్సోల్.WriteLine ( ఇటరేటర్.కరెంట్.విలువ ) ;
}
}
}
ఈ కోడ్ XmlDocumentని ఉపయోగించి “employees.xml” ఫైల్ను లోడ్ చేస్తుంది, పత్రం నుండి XPathNavigatorని సృష్టిస్తుంది మరియు

గమనిక: XML డాక్యుమెంట్ నుండి ఎలిమెంట్స్ మరియు అట్రిబ్యూట్లను ఎంచుకోవడానికి XPathని ఉపయోగించడం ఒక శక్తివంతమైన మరియు సౌకర్యవంతమైన మార్గం, కానీ మేము చర్చించిన కొన్ని ఇతర పద్ధతుల కంటే ఇది చాలా క్లిష్టంగా ఉంటుంది.
ముగింపు
XmlDocument తరగతిని ఉపయోగించడం పూర్తి DOM మానిప్యులేషన్ సామర్థ్యాలను అందిస్తుంది, అయితే ఇది ఇతర పద్ధతుల కంటే నెమ్మదిగా మరియు ఎక్కువ మెమరీ-ఇంటెన్సివ్గా ఉంటుంది. పెద్ద XML ఫైల్లను చదవడానికి XmlReader క్లాస్ మంచి ఎంపిక, ఎందుకంటే ఇది వేగవంతమైన, ఫార్వర్డ్-ఓన్లీ మరియు కాష్ చేయని స్ట్రీమ్-ఆధారిత విధానాన్ని అందిస్తుంది. XDocument క్లాస్ సరళమైన మరియు మరింత సంక్షిప్త వాక్యనిర్మాణాన్ని అందిస్తుంది, అయితే ఇది XmlReader వలె పని చేయకపోవచ్చు. అదనంగా, LINQ నుండి XML మరియు XPath పద్ధతులు XML ఫైల్ నుండి నిర్దిష్ట డేటాను సంగ్రహించడానికి శక్తివంతమైన ప్రశ్న సామర్థ్యాలను అందిస్తాయి.