Dalle-mini అనేది వినియోగదారు ఇన్పుట్ టెక్స్ట్ నుండి అధిక నాణ్యతతో కూడిన చిత్రాలను రూపొందించగల లోతైన అభ్యాస నమూనా. ఇది జనవరి 2021లో OpenAI విడుదల చేసిన DALL-E మోడల్పై ఆధారపడింది. DALL-E అంటే ' విడదీయబడిన భాష మరియు గుప్త వ్యక్తీకరణ ” అనేది ట్రాన్స్ఫార్మర్-ఆధారిత న్యూరల్ నెట్వర్క్, ఇది టెక్స్ట్ మరియు ఇమేజ్లను ఒక సాధారణ గుప్త స్థలంలోకి ఎన్కోడ్ చేయగలదు, ఆపై వాటిని తిరిగి ఏదో ఒక పద్ధతిలో డీకోడ్ చేస్తుంది.
ఈ వ్యాసం కింది కంటెంట్ను వివరిస్తుంది:
డల్లె-మినీ అంటే ఏమిటి?
ఆమెకు-మినీ ఇవ్వండి DALL-E యొక్క చిన్న మరియు వేగవంతమైన వెర్షన్, ఇది EleutherAI ద్వారా సృష్టించబడింది, ఇది ఓపెన్ సోర్స్ పరిశోధనా సమిష్టి. DALL-E యొక్క 12 బిలియన్లతో పోలిస్తే డాల్-మినీ 6 బిలియన్ పారామితులను మాత్రమే ఉపయోగిస్తుంది మరియు ఇది ఒకే GPUలో అమలు చేయగలదు. డల్లే-మినీ టెక్స్ట్ ఇన్పుట్ కోసం వేరొక టోకెనైజర్ మరియు పదజాలాన్ని కూడా ఉపయోగిస్తుంది, ఇది వివిధ భాషలు మరియు డొమైన్లతో మరింత అనుకూలంగా ఉండేలా చేస్తుంది:

గమనిక : వినియోగదారులు వీటిని అనుసరించడం ద్వారా Dalle-miniని ఉపయోగించి ఉచిత ధర చిత్రాలను రూపొందించవచ్చు లింక్ .
Dalle-mini యొక్క పని ఏమిటి?
డల్లె-మినీ వెనుక ఉన్న ప్రధాన ఆలోచన ట్రాన్స్ఫార్మర్ల శక్తి, ఇవి న్యూరల్ నెట్వర్క్లు. వారు టెక్స్ట్ లేదా ఇమేజ్ల వంటి సీక్వెన్షియల్ డేటాలో దీర్ఘ-శ్రేణి డిపెండెన్సీలు మరియు సంక్లిష్ట నమూనాలను నేర్చుకోవచ్చు.
ట్రాన్స్ఫార్మర్లు రెండు ప్రధాన భాగాలను కలిగి ఉంటాయి: ఎన్కోడర్ మరియు డీకోడర్. మొదటి భాగం ఇన్పుట్ (టెక్స్ట్ డిస్క్రిప్షన్) తీసుకుంటుంది మరియు దానిని దాచిన వెక్టర్లుగా మారుస్తుంది. ఆ తర్వాత, డీకోడర్ దానిని తీసుకుంటుంది మరియు ఇన్పుట్కు సంబంధించిన అవుట్పుట్ (ఒక చిత్రం)ని ఉత్పత్తి చేస్తుంది.
Dalle-mini మరియు DALL-E మధ్య తేడా ఏమిటి?
Dalle-mini మరియు DALL-E టెక్స్ట్ మరియు ఇమేజ్ల కోసం షేర్డ్ ఎన్కోడర్-డీకోడర్ ఆర్కిటెక్చర్ను ఉపయోగిస్తాయి. వారు ఒకే నెట్వర్క్ని ఉపయోగించి రెండు పద్ధతులను ఎన్కోడ్ చేయవచ్చు మరియు డీకోడ్ చేయవచ్చు. ఇది టెక్స్ట్ మరియు ఇమేజ్ల మధ్య అర్థ సంబంధాన్ని సంగ్రహించే సాధారణ గుప్త స్థలాన్ని తెలుసుకోవడానికి వారిని అనుమతిస్తుంది. ఆ తర్వాత, వాటిని టెక్స్ట్ లేదా వైస్ వెర్సా నుండి ఇమేజ్లను క్రియేట్ చేయడం వంటి క్రాస్-మోడల్ జనరేషన్ను నిర్వహించడానికి వీలు కల్పిస్తుంది.
Dalle-mini ఎలా పని చేస్తుంది?
వచన వివరణ నుండి చిత్రాన్ని రూపొందించడానికి, డల్లే-మినీ మొదట బైట్-పెయిర్ ఎన్కోడింగ్ (BPE) అల్గారిథమ్ని ఉపయోగించి వచనాన్ని టోకెనైజ్ చేస్తుంది, ఇది టెక్స్ట్ను వాటి ఫ్రీక్వెన్సీ మరియు సహ-సంభవం ఆధారంగా సబ్వర్డ్ యూనిట్లుగా విభజిస్తుంది:
డాల్-మినీ యొక్క అంతర్గత పనిని వివరంగా తెలుసుకుందాం:
డల్లె-మినీ యొక్క అంతర్గత పని
మనం అనుకుందాం, ' ఆడుతున్నారు ''గా విభజించబడవచ్చు ప్లా 'మరియు' యింగ్ ”. టోకెన్లు 8192 టోకెన్ల పదజాలాన్ని ఉపయోగించి సంఖ్యా IDలకు మ్యాప్ చేయబడతాయి. IDలు ఎన్కోడర్లోకి ఫీడ్ చేయబడి, పరిమాణం 256 x 64 యొక్క గుప్త ప్రాతినిధ్యాన్ని ఉత్పత్తి చేస్తాయి:
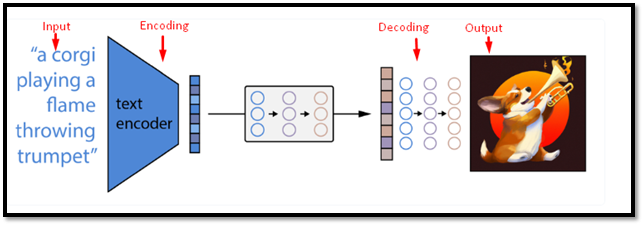
డీకోడర్ అప్పుడు గుప్త ప్రాతినిధ్యాన్ని తీసుకుంటుంది మరియు పరిమాణం 256 x 256 పిక్సెల్ల చిత్రాన్ని రూపొందిస్తుంది. డీకోడర్ ఆటోరిగ్రెసివ్ ప్రాసెస్ను ఉపయోగిస్తుంది, అంటే ఇది మునుపటి పిక్సెల్లు మరియు గుప్త ప్రాతినిధ్యంపై కండిషన్ చేయబడిన ప్రతి పిక్సెల్ను ఒక్కొక్కటిగా ఉత్పత్తి చేస్తుంది.
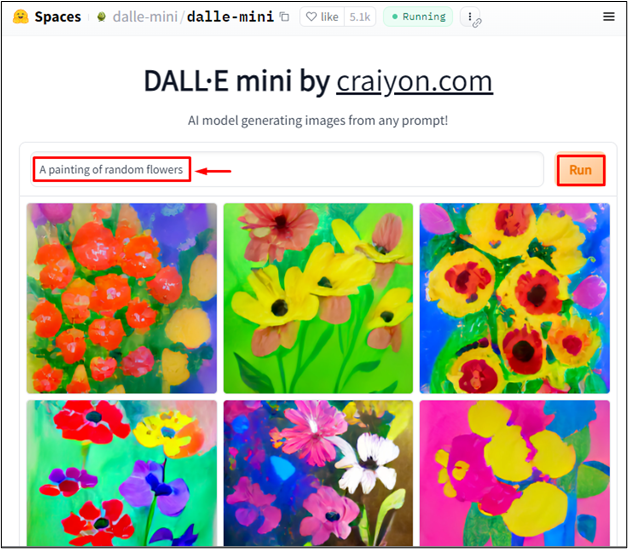
Dalle-miniని ఉపయోగించి టెక్స్ట్ వివరణ నుండి చిత్రాన్ని ఎలా రూపొందించాలి?
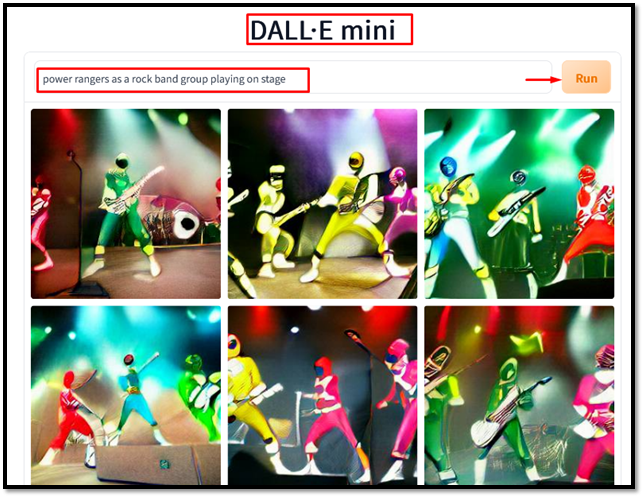
డాల్-మినీని ఉపయోగించి చిత్రం నుండి వచన వివరణను రూపొందించడానికి, ప్రాంప్ట్ విండోలో వచనాన్ని ఇన్పుట్ చేయండి. ఉదాహరణకు, టైప్ చేయండి ' యాదృచ్ఛిక పువ్వుల పెయింటింగ్ 'ప్రాంప్ట్లో మరియు' నొక్కండి పరుగు ”బటన్:
ఇన్పుట్ టెక్స్ట్ ప్రకారం డల్లె-మినీ సంబంధిత ఇమేజ్లను రూపొందించినట్లు అవుట్పుట్ చూపిస్తుంది.
ముగింపు
డాల్-మినీ అనేది క్రాస్-మోడల్ ఉత్పత్తికి ట్రాన్స్ఫార్మర్ల సామర్థ్యాన్ని ప్రదర్శించే ఒక అద్భుతమైన మోడల్. వారు సహజ భాషా వివరణల నుండి వాస్తవిక మరియు విభిన్న చిత్రాలను, అలాగే చిత్రాల నుండి పొందికైన మరియు సంబంధిత పాఠాలను సృష్టించగలరు. వారు ఒక చిత్రం లేదా వచనంలో బహుళ వస్తువులు లేదా లక్షణాలను కలపడం వంటి సంక్లిష్ట కూర్పులను కూడా నిర్వహించగలరు. ఈ వ్యాసం డల్లె-మినీ మరియు దాని పనిని వివరంగా వివరించింది.