కమాండ్ లైన్ వాతావరణంలో పని చేస్తున్నప్పుడు, ఫైళ్లు, డైరెక్టరీలు మరియు ఇతర డేటాను సమర్థవంతంగా నిర్వహించడానికి అందుబాటులో ఉన్న వివిధ ఆదేశాలపై బలమైన అవగాహన కలిగి ఉండటం చాలా అవసరం. అటువంటి ఆదేశం 'awk' కమాండ్. awk అనేది Unix/Linux వాతావరణంలో టెక్స్ట్ ఫైల్లను ప్రాసెస్ చేయడానికి మరియు మార్చడానికి ఉపయోగించే ఒక శక్తివంతమైన యుటిలిటీ. ఈ కథనం ‘awk’ కమాండ్ అంటే ఏమిటో మరియు దానిని సమర్థవంతంగా ఉపయోగించుకునే మార్గాలను వివరిస్తుంది.
'awk' కమాండ్ అంటే ఏమిటి?
'awk' కమాండ్ అనేది Unix/Linux పరిసరాలలో టెక్స్ట్ ఫైల్లను మార్చటానికి మరియు ప్రాసెస్ చేయడానికి ఒక శక్తివంతమైన సాధనం. ఇది నమూనా సరిపోలిక, ఫిల్టరింగ్, సార్టింగ్ మరియు డేటాను మార్చడం వంటి పనులను నిర్వహించడానికి ఉపయోగించవచ్చు. awk ప్రధానంగా నిర్మాణాత్మక పద్ధతిలో డేటాను ప్రాసెస్ చేయడానికి మరియు మార్చడానికి ఉపయోగించబడుతుంది.
awk కమాండ్ ఎలా ఉపయోగించాలి
awk అనేది వివిధ మార్గాల్లో ఉపయోగించబడే కమాండ్-లైన్ సాధనం. ఇది కమాండ్ లైన్ నుండి నేరుగా ప్రారంభించబడవచ్చు లేదా షెల్ స్క్రిప్ట్తో కలిపి ఉపయోగించవచ్చు. awkని ఎలా ఉపయోగించాలో ఇక్కడ కొన్ని ఉదాహరణలు ఉన్నాయి:
ఉదాహరణ 1: ఫైల్లోని లైన్ల సంఖ్యను లెక్కించడం
ఫైల్లోని పంక్తుల సంఖ్యను లెక్కించడానికి, మీరు క్రింది awk సింటాక్స్ని ఉపయోగించవచ్చు:
awk 'END{print NR}' < file-name.txt >
ఇక్కడ, “NR” అనేది ఒక అంతర్నిర్మిత వేరియబుల్, ఇది awk ద్వారా ప్రాసెస్ చేయబడిన రికార్డ్ల సంఖ్యను (లైన్లు) కలిగి ఉంటుంది. ఫైల్లోని అన్ని పంక్తులు ప్రాసెస్ చేయబడిన తర్వాత ఈ ఆదేశాన్ని అమలు చేయమని “END” కీవర్డ్ awkకి చెబుతుంది. ఇక్కడ నేను ఇలస్ట్రేషన్ ప్రయోజనాల కోసం ఫైల్ టెక్స్ట్ ఫైల్ని సృష్టించాను మరియు పై సింటాక్స్ని షెల్ స్క్రిప్ట్లో ఉపయోగించాను:
#!/బిన్/బాష్
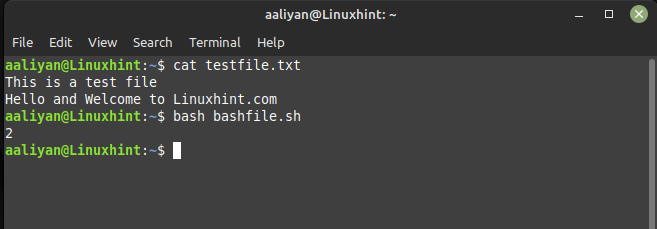
awk 'END{print NR}' testfile.txt
నేను సృష్టించిన టెక్స్ట్ ఫైల్లో రెండు పంక్తులు ఉన్నాయి మరియు awk కమాండ్ని ఉపయోగించినప్పుడు అవుట్పుట్ 2 ప్రదర్శించబడుతుంది, మీరు దిగువ చిత్రంలో నేను సృష్టించిన టెక్స్ట్ ఫైల్ను చూడవచ్చు:
ఉదాహరణ 2: వడపోత డేటా
నిర్దిష్ట ప్రమాణాల ఆధారంగా డేటాను ఫిల్టర్ చేయడానికి awkని ఉపయోగించవచ్చు మరియు అటువంటి ప్రయోజనం కోసం ఉపయోగించాల్సిన సింటాక్స్ ఇక్కడ ఉంది:
awk '!/<డేటా-టు-ఫిల్టర్>/' < file-name.txt >
ఉదాహరణకు, 'హలో' అనే పదాన్ని కలిగి ఉన్న ఫైల్లోని అన్ని పంక్తులను ఫిల్టర్ చేయడానికి మీరు దిగువ ఆదేశాన్ని ఉపయోగించవచ్చు.
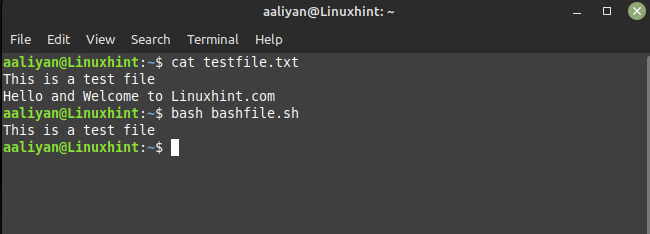
awk '!/హలో/' testfile.txt
ఈ ఉదాహరణలో, '!' చిహ్నం సాధారణ వ్యక్తీకరణ శోధనను నిరాకరిస్తుంది, కాబట్టి 'హలో' అనే పదాన్ని కలిగి లేని అన్ని పంక్తులు ముద్రించబడతాయి. నేను మునుపటి ఉదాహరణలో వలె అదే టెక్స్ట్ ఫైల్ని ఉపయోగించాను కాబట్టి పైన ఇచ్చిన స్క్రిప్ట్ యొక్క అవుట్పుట్ ఇక్కడ ఉంది:
ఉదాహరణ 3: నిర్దిష్ట ఫీల్డ్లను సంగ్రహించడం
awk ఫైల్ నుండి నిర్దిష్ట ఫీల్డ్లను సంగ్రహించడానికి కూడా ఉపయోగించవచ్చు. ఉదాహరణకు, మీరు పేర్లు మరియు చిరునామాల జాబితాను కలిగి ఉన్న ఫైల్ను కలిగి ఉంటే మరియు మీరు పేర్లను మాత్రమే సంగ్రహించాలనుకుంటే, మీరు ఈ క్రింది ఆదేశాన్ని ఉపయోగించవచ్చు:
awk '{print $
ఇక్కడ ఉదాహరణ కోసం, నేను అదే టెక్స్ట్ ఫైల్ యొక్క మొదటి ఫీల్డ్ను ప్రింట్ చేసాను మరియు “$1” ఫైల్లోని ప్రతి లైన్లోని మొదటి ఫీల్డ్ను సూచిస్తుంది. “ప్రింట్” ఆదేశం ఆ ఫీల్డ్ను మాత్రమే ప్రింట్ చేయమని awkకి చెబుతుంది.
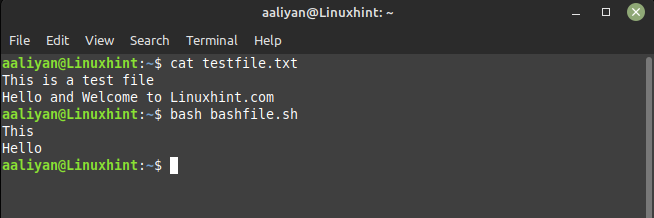
awk '{print $1}' testfile.txt
టెక్స్ట్ ఫైల్లో మొదటి పంక్తి యొక్క మొదటి ఎంట్రీ “ఇది” మరియు రెండవ పంక్తి యొక్క మొదటి ఎంట్రీ “హలో” కాబట్టి ఇక్కడ ఇచ్చిన కోడ్ అవుట్పుట్ ఉంది:
ముగింపు
awk కమాండ్ అనేది టెక్స్ట్ ఫైల్లను మార్చటానికి మరియు ప్రాసెస్ చేయడానికి ఉపయోగించే శక్తివంతమైన సాధనం. నిర్దిష్ట నిలువు వరుసలను ముద్రించడం, నమూనాల కోసం శోధించడం మరియు మొత్తాలను లెక్కించడం వంటి టెక్స్ట్ ఫైల్లపై వివిధ కార్యకలాపాలను నిర్వహించడానికి ఇది మిమ్మల్ని అనుమతిస్తుంది. awk యొక్క ప్రాథమిక అంశాలను ప్రావీణ్యం చేసుకోవడం ద్వారా, మీరు మీ వర్క్ఫ్లోను క్రమబద్ధీకరించవచ్చు మరియు మరింత సమర్థవంతమైన మరియు సమర్థవంతమైన Linux లేదా Unix వినియోగదారుగా మారవచ్చు.