సేకరణను సృష్టించండి
సూచికలను ఉపయోగించే ముందు, మేము మా MongoDBలో కొత్త సేకరణను సృష్టించాలి. మేము ఇప్పటికే ఒకదాన్ని సృష్టించాము మరియు 'డమ్మీ' పేరుతో 10 పత్రాలను చొప్పించాము. Find() MongoDB ఫంక్షన్ దిగువ MongoDB షెల్ స్క్రీన్పై “డమ్మీ” సేకరణ నుండి అన్ని రికార్డ్లను ప్రదర్శిస్తుంది.
test> db.Dummy.find() 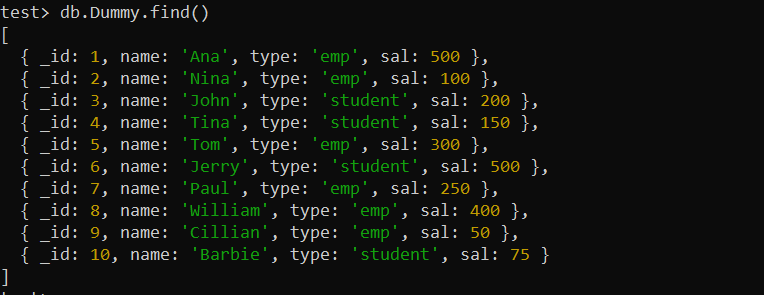
ఇండెక్సింగ్ రకాన్ని ఎంచుకోండి
ఇండెక్స్ని స్థాపించే ముందు, ప్రశ్న ప్రమాణాలలో సాధారణంగా ఉపయోగించబడే నిలువు వరుసలను మీరు ముందుగా గుర్తించాలి. తరచుగా ఫిల్టర్ చేయబడిన, క్రమబద్ధీకరించబడిన లేదా శోధించిన నిలువు వరుసలపై సూచికలు బాగా పని చేస్తాయి. పెద్ద కార్డినాలిటీ (అనేక విభిన్న విలువలు) ఉన్న ఫీల్డ్లు తరచుగా అద్భుతమైన ఇండెక్సింగ్ ఎంపికలు. విభిన్న ఇండెక్స్ రకాల కోసం ఇక్కడ కొన్ని కోడ్ ఉదాహరణలు ఉన్నాయి.
ఉదాహరణ 01: సింగిల్ ఫీల్డ్ ఇండెక్స్
ఇది బహుశా ఇండెక్స్ యొక్క అత్యంత ప్రాథమిక రకం, ఇది ఆ నిలువు వరుసలో ప్రశ్న వేగాన్ని పెంచడానికి ఒకే కాలమ్ను ఇండెక్స్ చేస్తుంది. సేకరణ రికార్డులను ప్రశ్నించడానికి మీరు ఒకే కీ ఫీల్డ్ని ఉపయోగించే ప్రశ్నల కోసం ఈ రకమైన సూచిక ఉపయోగించబడుతుంది. కింది విధంగా ఫైండ్ ఫంక్షన్లో 'డమ్మీ' సేకరణ యొక్క రికార్డులను ప్రశ్నించడానికి మీరు 'రకం' ఫీల్డ్ని ఉపయోగిస్తున్నారని భావించండి. ఈ ఆదేశం మొత్తం సేకరణను చూస్తుంది, ఇది భారీ సేకరణలను ప్రాసెస్ చేయడానికి చాలా సమయం పట్టవచ్చు. కాబట్టి, మేము ఈ ప్రశ్న యొక్క పనితీరును ఆప్టిమైజ్ చేయాలి.
test> db.Dummy.find({type: 'ఎంపీ' })
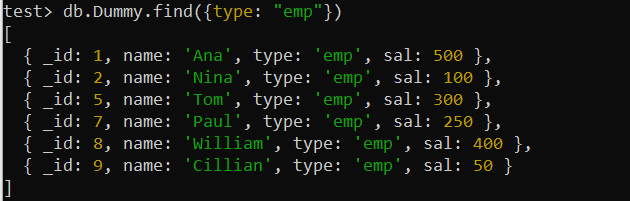
ఎగువన ఉన్న డమ్మీ సేకరణ యొక్క రికార్డులు 'రకం' ఫీల్డ్ని ఉపయోగించి కనుగొనబడ్డాయి, అంటే షరతును కలిగి ఉంది. కాబట్టి, శోధన ప్రశ్నను ఆప్టిమైజ్ చేయడానికి సింగిల్-కీ సూచికను ఇక్కడ ఉపయోగించవచ్చు. కాబట్టి, మేము 'డమ్మీ' సేకరణ యొక్క 'రకం' ఫీల్డ్లో సూచికను రూపొందించడానికి MongoDB యొక్క createIndex() ఫంక్షన్ని ఉపయోగిస్తాము. ఈ ప్రశ్నను ఉపయోగించడం యొక్క దృష్టాంతం షెల్పై “type_1” పేరుతో సింగిల్-కీ సూచిక యొక్క విజయవంతమైన సృష్టిని ప్రదర్శిస్తుంది.
test> db.Dummy.createIndex({ రకం: 1 })“టైప్” ఫీల్డ్ని ఉపయోగించుకున్న తర్వాత ఫైండ్() ప్రశ్నను ఉపయోగిస్తాము. ఇండెక్స్ స్థానంలో ఉన్నందున గతంలో ఉపయోగించిన ఫైండ్() ఫంక్షన్ కంటే ఇప్పుడు ఆపరేషన్ చాలా వేగంగా ఉంటుంది, ఎందుకంటే అభ్యర్థించిన ఉద్యోగ శీర్షికతో రికార్డ్లను వేగంగా తిరిగి పొందడానికి MongoDB సూచికను ఉపయోగించగలదు.
test> db.Dummy.find({type: 'ఎంపీ' })
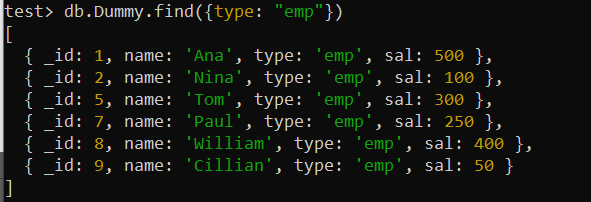
ఉదాహరణ 02: సమ్మేళనం సూచిక
మేము నిర్దిష్ట పరిస్థితులలో వివిధ ప్రమాణాల ఆధారంగా వస్తువుల కోసం వెతకాలనుకోవచ్చు. ఈ ఫీల్డ్ల కోసం సమ్మేళనం సూచికను అమలు చేయడం ప్రశ్న పనితీరును మెరుగుపరచడంలో సహాయపడుతుంది. ఈసారి, మీరు 'డమ్మీ' సేకరణ నుండి విభిన్న శోధన పరిస్థితులను కలిగి ఉన్న అనేక ఫీల్డ్లను ఉపయోగించి ప్రశ్నను ప్రదర్శిస్తున్నప్పుడు శోధించాలనుకుంటున్నారు. ఈ ప్రశ్న సేకరణ నుండి 'రకం' ఫీల్డ్ 'emp'కి సెట్ చేయబడిన రికార్డ్ల కోసం శోధిస్తోంది మరియు 'sal' ఫీల్డ్ 350 కంటే ఎక్కువ.
$gte లాజికల్ ఆపరేటర్ షరతును “sal” ఫీల్డ్కు వర్తింపజేయడానికి ఉపయోగించబడింది. మొత్తం 10 రికార్డ్లతో కూడిన మొత్తం కలెక్షన్లో వెతికిన తర్వాత మొత్తం రెండు రికార్డ్లు తిరిగి వచ్చాయి.
test> db.Dummy.find({type: 'ఎంపీ' , సాల్: {$gte: 350 } }) 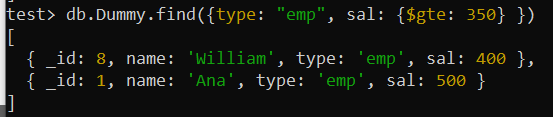
పైన పేర్కొన్న ప్రశ్న కోసం సమ్మేళనం సూచికను సృష్టిద్దాం. ఈ సమ్మేళనం సూచిక 'రకం' మరియు 'sal' ఫీల్డ్లను కలిగి ఉంది. '1' మరియు '-1' సంఖ్యలు వరుసగా 'రకం' మరియు 'sal' ఫీల్డ్ల కోసం ఆరోహణ మరియు అవరోహణ క్రమాన్ని సూచిస్తాయి. సమ్మేళనం సూచిక యొక్క నిలువు వరుసల క్రమం ముఖ్యమైనది మరియు ప్రశ్న నమూనాలకు అనుగుణంగా ఉండాలి. MongoDB ప్రదర్శించబడినట్లుగా ఈ సమ్మేళన సూచికకు “type_1_sal_-1” పేరును ఇచ్చింది.
test> db.Dummy.createIndex({ రకం: 1 , రెడీ:- 1 }) 
'emp' మరియు 'sal' ఫీల్డ్ విలువ 350 కంటే ఎక్కువ ఉన్న 'రకం' ఫీల్డ్ విలువతో రికార్డ్ల కోసం శోధించడానికి అదే ఫైండ్() ప్రశ్నను ఉపయోగించిన తర్వాత, మేము ఆర్డర్లో స్వల్ప మార్పుతో అదే అవుట్పుట్ను పొందాము మునుపటి ప్రశ్న ఫలితంతో పోలిస్తే. 'sal' ఫీల్డ్ కోసం పెద్ద విలువ రికార్డు ఇప్పుడు మొదటి స్థానంలో ఉంది, అయితే ఎగువ సమ్మేళనం సూచికలో 'sal' ఫీల్డ్ కోసం సెట్ చేసిన '-1' ప్రకారం చిన్నది అత్యల్పంగా ఉంది.
test> db.Dummy.find({type: 'ఎంపీ' , సాల్: {$gte: 350 } }) 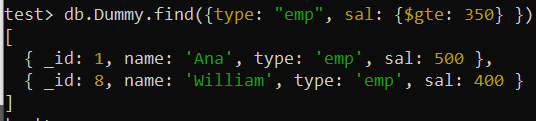
ఉదాహరణ 03: టెక్స్ట్ ఇండెక్స్
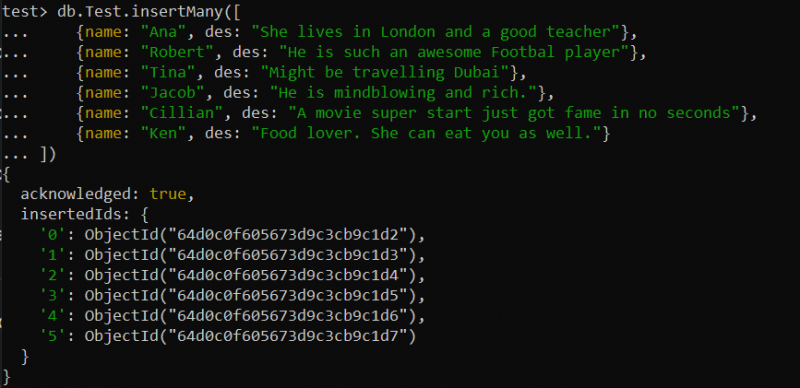
కొన్నిసార్లు, మీరు ఉత్పత్తులు, పదార్థాలు మొదలైన వాటి యొక్క పెద్ద వివరణలు వంటి పెద్ద డేటా సెట్తో వ్యవహరించాల్సిన పరిస్థితిని మీరు ఎదుర్కోవచ్చు. పెద్ద టెక్స్ట్ ఫీల్డ్లో పూర్తి-వచన శోధనలు చేయడానికి టెక్స్ట్ ఇండెక్స్ ఉపయోగకరంగా ఉండవచ్చు. ఉదాహరణకు, మేము మా పరీక్ష డేటాబేస్లో 'పరీక్ష' పేరుతో కొత్త సేకరణను సృష్టించాము. దిగువ కనుగొను() ప్రశ్న ప్రకారం insertMany() ఫంక్షన్ని ఉపయోగించి ఈ సేకరణలో మొత్తం 6 రికార్డ్లను చొప్పించారు.
test> db.Test.insertMany([{పేరు: 'అనా' , యొక్క: 'ఆమె లండన్లో నివసిస్తుంది మరియు మంచి ఉపాధ్యాయురాలు' },
{పేరు: 'రాబర్ట్' , యొక్క: 'అతను చాలా అద్భుతమైన ఫుట్బాల్ ఆటగాడు' },
{పేరు: 'నుండి' , యొక్క: 'దుబాయ్ ప్రయాణం కావచ్చు' },
{పేరు: 'జాకబ్' , యొక్క: 'అతను మనసును కదిలించేవాడు మరియు ధనవంతుడు.' },
{పేరు: 'సిలియన్' , యొక్క: 'సినిమా సూపర్ స్టార్ట్కి క్షణాల్లో పేరు వచ్చింది' },
{పేరు: 'కెన్' , యొక్క: 'ఆహార ప్రియురాలు. ఆమె నిన్ను కూడా తినగలదు.' }
])
ఇప్పుడు, మేము ఈ సేకరణ యొక్క 'Des' ఫీల్డ్లో MongoDB యొక్క createIndex() ఫంక్షన్ని ఉపయోగించి టెక్స్ట్ ఇండెక్స్ని సృష్టిస్తాము. ఫీల్డ్ విలువలోని 'టెక్స్ట్' అనే కీవర్డ్ ఇండెక్స్ రకాన్ని ప్రదర్శిస్తుంది, ఇది 'టెక్స్ట్' ఇండెక్స్. ఇండెక్స్ పేరు, des_text, స్వయంచాలకంగా రూపొందించబడింది.
test> db.Test.createIndex({des: 'వచనం' })ఇప్పుడు, “des_text” ఇండెక్స్ ద్వారా సేకరణలో “టెక్స్ట్-సెర్చ్” చేయడానికి find() ఫంక్షన్ ఉపయోగించబడుతుంది. సేకరణ రికార్డులలో 'ఆహారం' అనే పదం కోసం శోధించడానికి మరియు నిర్దిష్ట రికార్డ్ను ప్రదర్శించడానికి $శోధన ఆపరేటర్ ఉపయోగించబడింది.
test> db.Test.find({ $text: { $search: 'ఆహారం' }}); 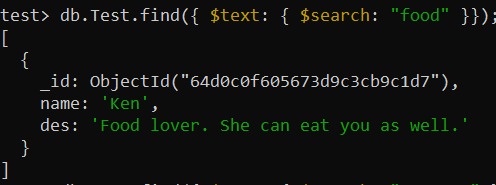
సూచికలను ధృవీకరించండి:
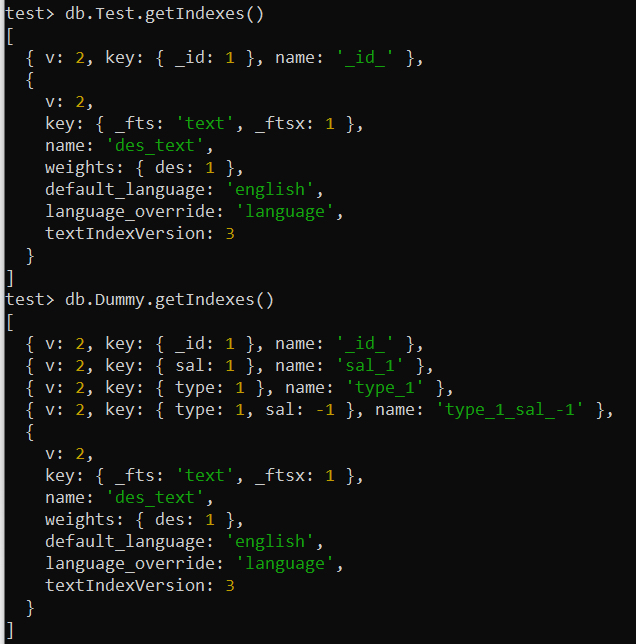
మీరు మీ MongoDBలో వివిధ సేకరణల యొక్క అన్ని అనువర్తిత సూచికలను తనిఖీ చేయవచ్చు మరియు జాబితా చేయవచ్చు. దీని కోసం, మీ MongoDB షెల్ స్క్రీన్లో సేకరణ పేరుతో పాటు getIndexes() పద్ధతిని ఉపయోగించండి. 'పరీక్ష' మరియు 'డమ్మీ' సేకరణల కోసం మేము ఈ ఆదేశాన్ని విడిగా ఉపయోగించాము. ఇది మీ స్క్రీన్పై అంతర్నిర్మిత మరియు వినియోగదారు నిర్వచించిన సూచికలకు సంబంధించి అవసరమైన మొత్తం సమాచారాన్ని చూపుతుంది.
పరీక్ష> db.Test.getIndexes()test> db.Dummy.getIndexes()
డ్రాప్ ఇండెక్స్లు:
ఇండెక్స్ వర్తింపజేసిన అదే ఫీల్డ్ పేరుతో పాటు డ్రాప్ఇండెక్స్() ఫంక్షన్ను ఉపయోగించి సేకరణ కోసం గతంలో సృష్టించిన సూచికలను తొలగించాల్సిన సమయం ఇది. దిగువ ప్రశ్న సింగిల్ ఇండెక్స్ తీసివేయబడిందని చూపిస్తుంది.
test> db.Dummy.dropIndex({రకం: 1 }) 
అదే విధంగా, సమ్మేళనం సూచికను తగ్గించవచ్చు.
test> db.Dummy.drop సూచిక({రకం: 1 , రెడీ: 1 }) 
ముగింపు
MongoDB నుండి డేటాను తిరిగి పొందడాన్ని వేగవంతం చేయడం ద్వారా, ప్రశ్నల సామర్థ్యాన్ని పెంచడానికి ఇండెక్సింగ్ అవసరం. సూచికలు లేనందున, మొంగోడిబి తప్పనిసరిగా సరిపోలే రికార్డుల కోసం మొత్తం సేకరణను శోధించాలి, ఇది సెట్ పరిమాణం పెరిగేకొద్దీ తక్కువ ప్రభావవంతంగా మారుతుంది. ఇండెక్స్ డేటాబేస్ నిర్మాణాన్ని ఉపయోగించి సరైన రికార్డులను వేగంగా కనుగొనగల MongoDB సామర్థ్యం, తగిన ఇండెక్సింగ్ ఉపయోగించినప్పుడు ప్రశ్నల ప్రాసెసింగ్ను వేగవంతం చేస్తుంది.