కొన్నిసార్లు ఇచ్చిన డేటాసెట్ ఒకే CSV ఫైల్లో ఉండదు. అవన్నీ వేర్వేరు ఎక్సెల్ షీట్లలో ఉన్నాయి. అనేక డేటాసెట్లకు బదులుగా ఒకే డేటాసెట్లో అన్ని గణన లేదా ప్రీప్రాసెసింగ్ కార్యకలాపాలను నిర్వహించడం ఉత్తమమని మీకు ఇప్పటికే తెలుసు. ఇది ప్రీప్రాసెసింగ్ టాస్క్లపై మనం ఖర్చు చేయాల్సిన సమయాన్ని తగ్గిస్తుంది లేదా ఆదా చేస్తుంది. అలాగే, ఒక డేటా అనలిస్ట్ లేదా డేటా సైంటిస్ట్గా, మీరు మీ విశ్లేషణ లేదా అందుబాటులో ఉన్న డేటాను పరిశీలించే ముందు తప్పనిసరిగా విలీనం చేయవలసిన అనేక CSV ఫైల్ల ద్వారా మీరు తరచుగా ఓవర్లోడ్ చేయబడవచ్చు. మరోవైపు, అన్ని ఫైల్లు ఒకే లేదా ఒకే డేటా మూలం నుండి పొందడం మరియు ఒకే కాలమ్/వేరియబుల్స్ పేర్లు మరియు డేటా నిర్మాణాన్ని కలిగి ఉండటం ఎల్లప్పుడూ సాధ్యం కాదు. ఈ పోస్ట్ రెండు లేదా అంతకంటే ఎక్కువ CSV ఫైల్లను సారూప్య లేదా భిన్నమైన నిలువు వరుస నిర్మాణంతో కలపడం నేర్పుతుంది.
CSV ఫైల్లను ఎందుకు కలపాలి?
డేటా సెట్ అనేది ఒక నిర్దిష్ట అంశానికి సంబంధించిన విలువలు లేదా సంఖ్యల సేకరణ లేదా సమూహం కావచ్చు. ఉదాహరణకు, ఒక నిర్దిష్ట తరగతిలో ప్రతి విద్యార్థి యొక్క పరీక్ష ఫలితాలు డేటాసెట్కి ఉదాహరణ. పెద్ద డేటాసెట్ల పరిమాణం కారణంగా, అవి తరచుగా వేర్వేరు వర్గాల కోసం ప్రత్యేక CSV ఫైల్లలో నిల్వ చేయబడతాయి. ఉదాహరణకు, మేము ఒక నిర్దిష్ట వ్యాధి కోసం రోగిని పరీక్షించవలసి వస్తే, వారి లింగం, వైద్య రికార్డు, వయస్సు, వ్యాధి యొక్క తీవ్రత మొదలైన వాటితో సహా ప్రతి భాగాన్ని మనం తప్పనిసరిగా పరిగణించాలి. తత్ఫలితంగా, వివిధ అంచనాలను ప్రభావితం చేసే అంశాలను పరిశీలించడానికి CSV డేటాను కలపడం అవసరం. అంశాలను. అలాగే, గణన లేదా ప్రీప్రాసెసింగ్ పనులను చేస్తున్నప్పుడు అనేక డేటాసెట్ల కంటే ఒకే డేటాసెట్ను పని చేయడం మరియు నిర్వహించడం ఉత్తమం. ఇది మెమరీ మరియు ఇతర గణన వనరులను ఆదా చేస్తుంది
పైథాన్లో CSV ఫైల్లను ఎలా కలపాలి?
పైథాన్లో రెండు లేదా అంతకంటే ఎక్కువ CSV ఫైల్లను కలపడానికి అనేక మార్గాలు మరియు పద్ధతులు ఉన్నాయి. దిగువ విభాగంలో, మేము CSV ఫైల్లను పాండాస్ డేటాఫ్రేమ్లో కలపడం కోసం append(), concat(), మరియు merge() ఫంక్షన్లు మొదలైన వాటిని ఉపయోగిస్తాము, ఆపై డేటాఫ్రేమ్లు ఒకే CSV ఫైల్గా మార్చబడతాయి. ఒకే విధమైన లేదా వేరియబుల్ నిలువు వరుస నిర్మాణంతో బహుళ CSV ఫైల్లను ఎలా కలపాలో మేము బోధిస్తాము.
విధానం # 1: CSVలను సారూప్య నిర్మాణాలు లేదా నిలువు వరుసలతో కలపడం
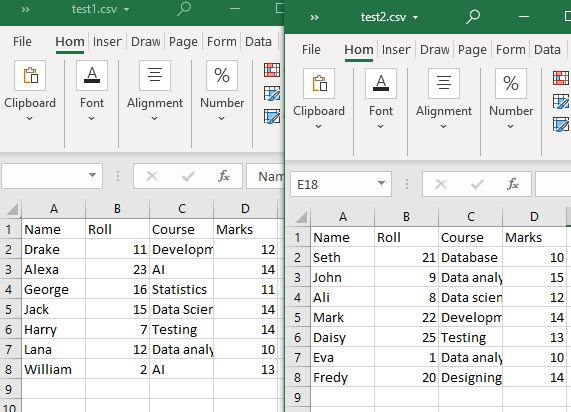
మా ప్రస్తుత వర్కింగ్ డైరెక్టరీలో “test1” మరియు “test2” అనే రెండు CSV ఫైల్లు ఉన్నాయి.
ఉదాహరణ # 1: append() ఫంక్షన్ని ఉపయోగించడం
రెండు CSV ఫైల్లు ఒకే నిర్మాణాన్ని కలిగి ఉంటాయి. వర్కింగ్ డైరెక్టరీలో CSV ఫైల్లను మాత్రమే జాబితా చేయడానికి ఈ పద్ధతిలో గ్లోబ్() ఫంక్షన్ ఉపయోగించబడుతుంది. అప్పుడు మన CSV ఫైల్లను (సాధారణ పట్టిక నిర్మాణంతో) చదవడానికి “pandas.DataFrame.append()”ని ఉపయోగిస్తాము.

అవుట్పుట్:
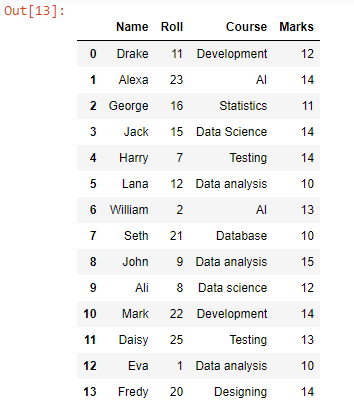
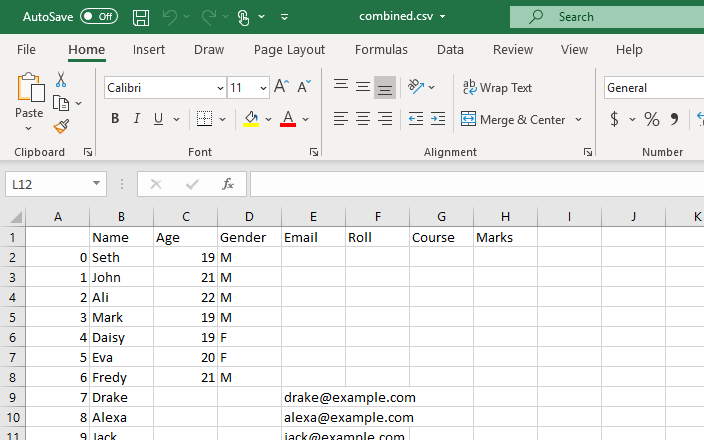
append ఫంక్షన్ని ఉపయోగించి, మేము test1.csv యొక్క డేటా వరుసల క్రింద test2.csv నుండి ప్రతి డేటా అడ్డు వరుసను జోడించాము లేదా జోడించాము, ఎందుకంటే ఫైల్ యొక్క అన్ని డేటా అడ్డు వరుసలు కలపబడినట్లు చూడవచ్చు. ఈ డేటాఫ్రేమ్ను CSVకి మార్చడానికి, మేము to_csv() ఫంక్షన్ని ఉపయోగించవచ్చు.

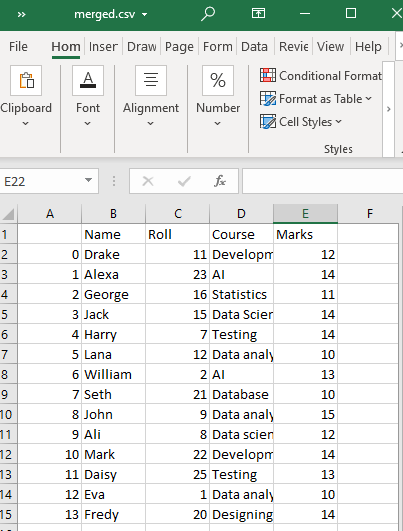
ఇది మా వర్కింగ్ డైరెక్టరీలో పేర్కొన్న పేరుతో, అంటే merged.csvతో 'test1' మరియు 'test2' యొక్క CSV ఫైల్ల మిశ్రమ CSV ఫైల్ను సృష్టిస్తుంది.
ఉదాహరణ # 2: concat() ఫంక్షన్ని ఉపయోగించడం
మేము ముందుగా పాండాస్ మాడ్యూల్ని దిగుమతి చేస్తాము. మ్యాప్ పద్ధతి మేము పాస్ చేసిన ప్రతి CSV ఫైల్ను pd.read_csv()ని ఉపయోగించి రీడ్ చేస్తుంది. ఈ మ్యాప్ చేయబడిన ఫైల్లు (CSV ఫైల్లు) pd.concat() ఫంక్షన్ని ఉపయోగించి డిఫాల్ట్గా అడ్డు వరుస అక్షం వెంట కలపబడతాయి. మేము CSV ఫైల్లను క్షితిజ సమాంతరంగా కలపాలనుకుంటే, మేము axis=1ని పాస్ చేయవచ్చు. నిర్లక్ష్య సూచికను పేర్కొనడం = ట్రూ కలిపి డేటాఫ్రేమ్ కోసం నిరంతర సూచిక విలువలను కూడా సృష్టిస్తుంది.

pd.read_csv() CSV ఫైల్లను సంయోగం తర్వాత పాండాస్ డేటాఫ్రేమ్లోకి చదవడానికి concat() ఫంక్షన్ లోపల పంపబడుతుంది.
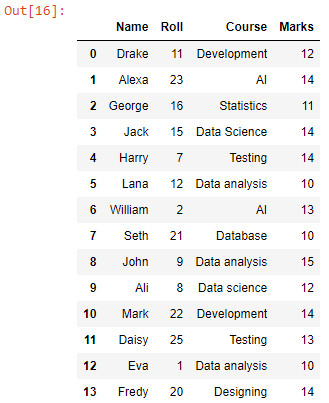
మేము వర్కింగ్ డైరెక్టరీలోని అన్ని CSV ఫైల్ల సంయుక్త డేటాతో డేటాఫ్రేమ్ని పొందాము. ఇప్పుడు, దానిని CSV ఫైల్గా మారుద్దాం.
మా సంయుక్త CSV ప్రస్తుత డైరెక్టరీలో సృష్టించబడింది.
విధానం # 2: విభిన్న నిర్మాణాలు లేదా నిలువు వరుసలతో CSVలను కలపడం
మేము మొదటి పద్ధతిలో అదే నిలువు వరుసలు మరియు నిర్మాణంతో CSV ఫైల్లను కలపడం గురించి చర్చించాము. ఈ పద్ధతిలో, మేము వివిధ నిలువు వరుసలు మరియు నిర్మాణాలతో CSV ఫైల్లను మిళితం చేస్తాము.
ఉదాహరణ # 1: విలీనం() ఫంక్షన్ని ఉపయోగించడం
పాండాస్ మాడ్యూల్లోని “pandas.merge()” ఫంక్షన్ రెండు CSV ఫైల్లను మిళితం చేయగలదు. విలీనం చేయడం అనేది భాగస్వామ్య నిలువు వరుసలు లేదా లక్షణాల ఆధారంగా రెండు డేటాసెట్లను ఒకే డేటాసెట్లో కలపడాన్ని సూచిస్తుంది.
మేము చేరడానికి నాలుగు విభిన్న మార్గాలలో డేటాఫ్రేమ్లను విలీనం చేయవచ్చు:
- లోపలి
- కుడి
- ఎడమ
- బయటి
ఈ రకమైన విలీనాలను నిర్వహించడానికి, మేము రెండు CSV ఫైల్లను ఉపయోగిస్తాము.
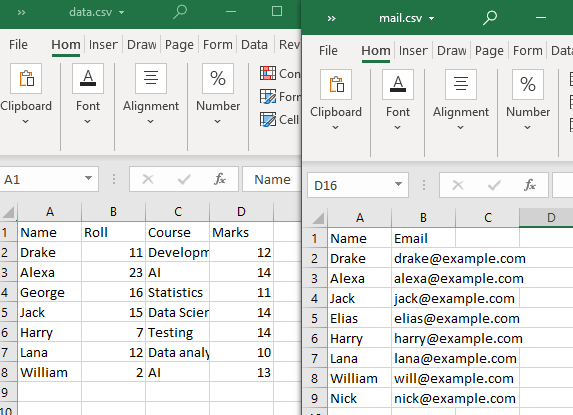
రెండు CSV ఫైల్లు తప్పనిసరిగా కనీసం ఒక లక్షణం లేదా నిలువు వరుసను భాగస్వామ్యం చేయాలని గుర్తుంచుకోండి. గమనించినట్లుగా, నిలువు వరుస “పేరు” మరియు దానిలోని కొన్ని లక్షణాలు రెండు CSV ఫైల్ల ద్వారా భాగస్వామ్యం చేయబడతాయి.
ఇన్నర్ జాయిన్ ఉపయోగించి విలీనం చేయండి
విలీనం() ఫంక్షన్లో పరామితి how='inner'ని పేర్కొనడం వలన పేర్కొన్న నిలువు వరుస ప్రకారం రెండు డేటాఫ్రేమ్లను మిళితం చేస్తుంది, ఆపై రెండు ఒరిజినల్ డేటాఫ్రేమ్లలో ఒకేలాంటి/అదే విలువలతో అడ్డు వరుసలను మాత్రమే కలిగి ఉండే కొత్త డేటాఫ్రేమ్ను అందిస్తుంది.
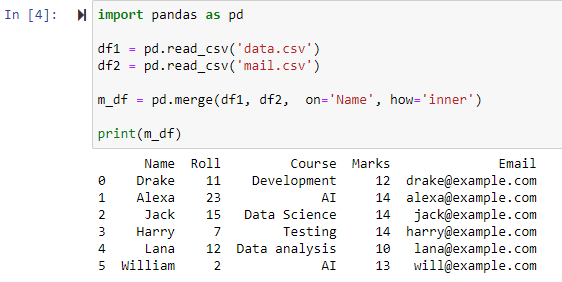
ఫంక్షన్ రెండు CSV ఫైల్లను విలీనం చేసిందని మరియు నిలువు వరుస 'పేరు' యొక్క సాధారణ లక్షణాల ఆధారంగా వరుసలను తిరిగి అందించిందని చూడవచ్చు.
కుడి ఔటర్ జాయిన్ ఉపయోగించి విలీనం చేయండి
పరామితి ఎలా='కుడి' పేర్కొనబడినప్పుడు, రెండు డేటాఫ్రేమ్లు 'ఆన్' పరామితి కోసం మేము పేర్కొన్న నిలువు వరుస ఆధారంగా కలపబడతాయి. ఎడమ డేటాఫ్రేమ్ విలువలు లేని ఏవైనా అడ్డు వరుసలతో సహా కుడి డేటాఫ్రేమ్ నుండి అన్ని అడ్డు వరుసలను కలిగి ఉన్న కొత్త డేటాఫ్రేమ్, ఎడమ డేటాఫ్రేమ్ యొక్క కాలమ్ విలువ NANకి సెట్ చేయబడి అందించబడుతుంది.
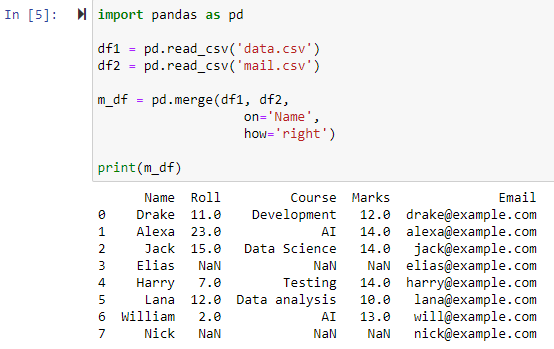
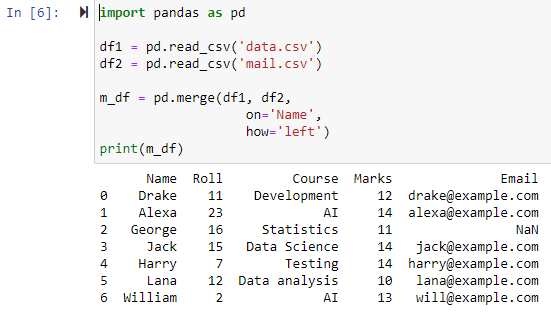
లెఫ్ట్ ఔటర్ జాయిన్ ఉపయోగించి విలీనం చేయండి
పారామీటర్ను 'ఎడమ'గా ఎలా పేర్కొన్నప్పుడు, 'ఆన్' పరామితిని ఉపయోగించి పేర్కొన్న నిలువు వరుస ఆధారంగా రెండు డేటాఫ్రేమ్లు మిళితం చేయబడతాయి, ఎడమ డేటాఫ్రేమ్లోని అన్ని అడ్డు వరుసలు అలాగే NAN ఉన్న ఏవైనా అడ్డు వరుసలను కలిగి ఉన్న కొత్త డేటాఫ్రేమ్ను తిరిగి అందిస్తుంది. లేదా కుడి డేటాఫ్రేమ్లో శూన్య విలువలు మరియు సరైన డేటాఫ్రేమ్ కాలమ్ విలువను NANకి సెట్ చేస్తుంది.
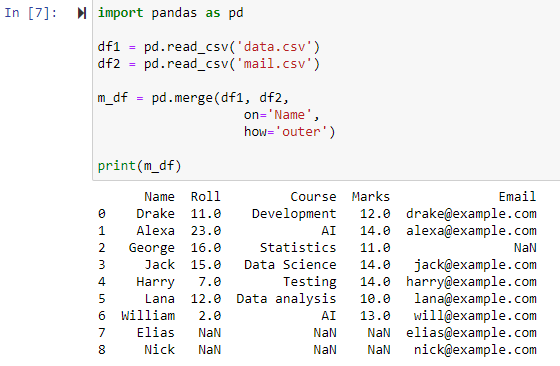
పూర్తి ఔటర్ జాయిన్ ఉపయోగించి విలీనం చేయండి
how='outer' పేర్కొనబడినప్పుడు, 'ఆన్' పరామితి కోసం పేర్కొన్న కాలమ్పై ఆధారపడి రెండు డేటాఫ్రేమ్లు మిళితం చేయబడతాయి, df1 మరియు df2 డేటాఫ్రేమ్లు రెండింటి నుండి అడ్డు వరుసలను కలిగి ఉన్న కొత్త డేటాఫ్రేమ్ను తిరిగి ఇస్తుంది మరియు ఏదైనా అడ్డు వరుసల విలువగా NANని సెట్ చేస్తుంది. దీని కోసం డేటాఫ్రేమ్లలో ఒకదానిలో డేటా లేదు.
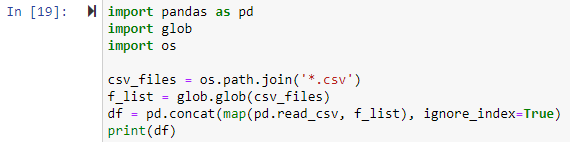
ఉదాహరణ # 2: వర్కింగ్ డైరెక్టరీలో అన్ని CSV ఫైల్లను కలపడం
ఈ పద్ధతిలో, మేము అన్ని .csv ఫైల్లను పాండాస్ డేటాఫ్రేమ్లో కలపడానికి గ్లోబ్ మాడ్యూల్ని ఉపయోగిస్తాము. అన్ని లైబ్రరీలను ముందుగా దిగుమతి చేసుకోవాలి. తర్వాత, మనం కలపాలనుకుంటున్న ప్రతి CSV ఫైల్కు పాత్ను సెట్ చేస్తాము. దిగువ ఉదాహరణలో os.path.join() ఫంక్షన్కి ఫైల్ పాత్ మొదటి ఆర్గ్యుమెంట్, మరియు రెండవ ఆర్గ్యుమెంట్ పాత్ కాంపోనెంట్లు లేదా .csv ఫైల్లు చేరాలి. ఇక్కడ, '*.csv' అనే వ్యక్తీకరణ .csv ఫైల్ పొడిగింపుతో ముగిసే వర్కింగ్ డైరెక్టరీలోని ప్రతి ఫైల్ని కనుగొని, తిరిగి అందిస్తుంది. glob.glob(ఫైల్స్ చేరినవి) ఫంక్షన్ విలీనం చేయబడిన ఫైల్ల పేర్ల జాబితాను ఇన్పుట్గా అంగీకరిస్తుంది మరియు అన్ని విలీన/కలిపి ఫైళ్ల జాబితాను అవుట్పుట్ చేస్తుంది.
ఈ స్క్రిప్ట్ మా పని చేసే డైరెక్టరీలోని అన్ని CSV ఫైల్ల సంయుక్త డేటాతో డేటాఫ్రేమ్ను అందిస్తుంది.
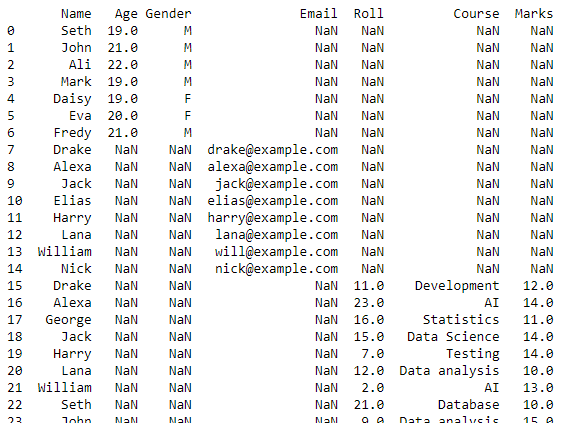
ఈ డేటాఫ్రేమ్ CSV ఫైల్గా రూపాంతరం చెందుతుంది మరియు ఈ మార్పిడి కోసం to_csv() ఫంక్షన్ ఉపయోగించబడుతుంది. ఈ కొత్త CSV ఫైల్ ప్రస్తుత వర్కింగ్ డైరెక్టరీలో నిల్వ చేయబడిన అన్ని CSV ఫైల్ల నుండి సృష్టించబడిన మిశ్రమ CSV ఫైల్లు.
ముగింపు
ఈ పోస్ట్లో, మనం CSV ఫైల్లను ఎందుకు కలపాలి అని చర్చించాము. పైథాన్లో రెండు లేదా అంతకంటే ఎక్కువ CSV ఫైల్లను ఎలా కలపవచ్చో మేము చర్చించాము. మేము ఈ ట్యుటోరియల్ని రెండు విభాగాలుగా విభజించాము. మొదటి విభాగంలో, ఒకే నిర్మాణం లేదా నిలువు వరుస పేర్లతో కూడిన CSV ఫైల్లను కలపడానికి append() మరియు concat() ఫంక్షన్లను ఎలా ఉపయోగించాలో మేము వివరించాము. రెండవ విభాగంలో, మేము వివిధ నిలువు వరుసలు మరియు నిర్మాణాల యొక్క CSV ఫైల్లను కలపడం కోసం merge() పద్ధతి, os.path.join(), మరియు గ్లోబ్ పద్ధతిని ఉపయోగించాము.