ఉదాహరణ 1:
'iostream' అనేది C++ యొక్క విధులు ప్రకటించబడిన మొదటి హెడర్ ఫైల్. అప్పుడు, మేము వెక్టర్తో పని చేయడానికి మరియు వెక్టర్లపై పనిచేయడానికి ఇక్కడ చేర్చబడిన “వెక్టర్” హెడర్ ఫైల్ను జోడిస్తాము. అప్పుడు, “std” అనేది మనం ఇక్కడ చొప్పించే నేమ్స్పేస్, కాబట్టి మేము ఈ కోడ్లో అన్ని ఫంక్షన్లతో ఈ “std”ని వ్యక్తిగతంగా ఉంచాల్సిన అవసరం లేదు. అప్పుడు, 'ప్రధాన()' ఇక్కడ సూచించబడుతుంది. దీని కింద, మేము 'int' డేటా రకం యొక్క వెక్టర్ను 'myNewData' పేరుతో సృష్టిస్తాము మరియు దానిలో కొన్ని పూర్ణాంక విలువలను చొప్పించాము.
దీని తర్వాత, మేము 'ఫర్' లూప్ను ఉంచుతాము మరియు దానిలో ఈ 'ఆటో' కీవర్డ్ని ఉపయోగిస్తాము. ఇప్పుడు, ఈ ఇటరేటర్ ఇక్కడ ఉన్న విలువల డేటా రకాన్ని గుర్తిస్తుంది. మేము 'myNewData' వెక్టర్ యొక్క విలువలను పొందుతాము మరియు వాటిని 'డేటా' వేరియబుల్లో సేవ్ చేస్తాము మరియు 'కౌట్'లో ఈ 'డేటా'ని జోడించినప్పుడు వాటిని ఇక్కడ కూడా ప్రదర్శిస్తాము.
కోడ్ 1:
#
#
ఉపయోగించి నేమ్స్పేస్ std ;
int ప్రధాన ( ) {
వెక్టర్ < int > myNewData { పదకొండు , 22 , 33 , 44 , 55 , 66 } ;
కోసం ( దానంతట అదే సమాచారం : myNewData ) {
కోట్ << సమాచారం << endl ;
}
}
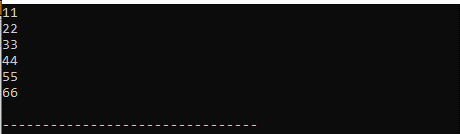
అవుట్పుట్ :
మేము ఇక్కడ ముద్రించిన ఈ వెక్టర్ యొక్క అన్ని విలువలను చూశాము. 'ఫర్' లూప్ని ఉపయోగించడం ద్వారా మరియు దానిలో 'ఆటో' కీవర్డ్ని ఉంచడం ద్వారా మేము ఈ విలువలను ప్రింట్ చేస్తాము.
ఉదాహరణ 2:
ఇక్కడ, మేము “bits/stdc++.h”ని జోడిస్తాము ఎందుకంటే ఇది అన్ని ఫంక్షన్ డిక్లరేషన్లను కలిగి ఉంటుంది. అప్పుడు, మేము ఇక్కడ “std” నేమ్స్పేస్ని ఉంచాము మరియు ఆపై “main()”ని అమలు చేస్తాము. దీని క్రింద, మేము 'స్ట్రింగ్' యొక్క 'సెట్'ని ప్రారంభించాము మరియు దానికి 'myString' అని పేరు పెట్టాము. అప్పుడు, తదుపరి లైన్లో, మేము దానిలో స్ట్రింగ్ డేటాను ఇన్సర్ట్ చేస్తాము. మేము 'ఇన్సర్ట్()' పద్ధతిని ఉపయోగించి ఈ సెట్లో కొన్ని పండ్ల పేర్లను చొప్పించాము.
మేము దీని కింద 'ఫర్' లూప్ని ఉపయోగిస్తాము మరియు దానిలో 'ఆటో' కీవర్డ్ని ఉంచుతాము. దీని తర్వాత, మేము 'ఆటో' కీవర్డ్తో 'my_it' పేరుతో ఇటరేటర్ని ప్రారంభించాము మరియు దీనికి 'begin()' ఫంక్షన్తో పాటు 'myString'ని కేటాయించాము.
అప్పుడు, మేము 'my_it' 'myString.end()'కి సమానం కాని షరతును ఉంచుతాము మరియు 'my_it++'ని ఉపయోగించి ఇటరేటర్ విలువను పెంచుతాము. దీని తర్వాత, మేము '*my_it'ని 'కౌట్'లో ఉంచుతాము. ఇప్పుడు, ఇది ఆల్ఫాబెటిక్ సీక్వెన్స్ ప్రకారం పండ్ల పేర్లను ప్రింట్ చేస్తుంది మరియు మనం ఇక్కడ “ఆటో” కీవర్డ్ని ఉంచినప్పుడు డేటా రకం స్వయంచాలకంగా గుర్తించబడుతుంది.
కోడ్ 2:
#ఉపయోగించి నేమ్స్పేస్ std ;
int ప్రధాన ( )
{
సెట్ < స్ట్రింగ్ > myString ;
myString. చొప్పించు ( { 'ద్రాక్ష' , 'నారింజ' , 'అరటి' , 'పియర్' , 'యాపిల్' } ) ;
కోసం ( దానంతట అదే నా_అది = myString. ప్రారంభం ( ) ; నా_అది ! = myString. ముగింపు ( ) ; నా_అది ++ )
కోట్ << * నా_అది << '' ;
తిరిగి 0 ;
}
అవుట్పుట్:
ఇక్కడ, పండ్ల పేర్లు అక్షర క్రమంలో ప్రదర్శించబడటం మనం గమనించవచ్చు. మేము స్ట్రింగ్ సెట్లో చొప్పించిన మొత్తం డేటా ఇక్కడ రెండర్ చేయబడింది, ఎందుకంటే మేము మునుపటి కోడ్లో “కోసం” మరియు “ఆటో” ఉపయోగించాము.

ఉదాహరణ 3:
“bits/stdc++.h” ఇప్పటికే అన్ని ఫంక్షన్ డిక్లరేషన్లను కలిగి ఉన్నందున, మేము దానిని ఇక్కడ జోడిస్తాము. “std” నేమ్స్పేస్ని జోడించిన తర్వాత, మేము ఈ స్థానం నుండి “main()” అని పిలుస్తాము. కింది వాటిలో మనం స్థాపించిన “పూర్ణాంక” యొక్క “సెట్”ని “myIntegers” అంటారు. అప్పుడు, మేము అనుసరించిన లైన్లో పూర్ణాంక డేటాను జోడిస్తాము. ఈ జాబితాకు కొన్ని పూర్ణాంకాలను జోడించడానికి మేము “ఇన్సర్ట్()” పద్ధతిని ఉపయోగిస్తాము. 'ఆటో' కీవర్డ్ ఇప్పుడు దీని కింద ఉపయోగించబడే 'ఫర్' లూప్లోకి చొప్పించబడింది.
తర్వాత, “new_it” పేరుతో ఇటరేటర్ని ప్రారంభించేందుకు “ఆటో” కీవర్డ్ని ఉపయోగిస్తాము, దానికి “myIntegers” మరియు “begin()” ఫంక్షన్లను కేటాయిస్తాము. తర్వాత, మేము 'my_it' తప్పనిసరిగా 'myIntegers.end()'కి సమానంగా ఉండకూడదని మరియు ఇరేటర్ విలువను పెంచడానికి 'new_it++'ని ఉపయోగించాలని సూచించే షరతును సెటప్ చేస్తాము. తరువాత, మేము ఈ 'కౌట్' విభాగంలో '*new_it'ని ఇన్సర్ట్ చేస్తాము. ఇది పూర్ణాంకాలను ఆరోహణంగా ముద్రిస్తుంది. “ఆటో” కీవర్డ్ చొప్పించబడినందున, ఇది స్వయంచాలకంగా డేటా రకాన్ని గుర్తిస్తుంది.
కోడ్ 3:
#ఉపయోగించి నేమ్స్పేస్ std ;
int ప్రధాన ( )
{
సెట్ < int > నా పూర్ణాంకాలు ;
నా పూర్ణాంకాలు. చొప్పించు ( { నాలుగు ఐదు , 31 , 87 , 14 , 97 , ఇరవై ఒకటి , 55 } ) ;
కోసం ( దానంతట అదే కొత్త_అది = నా పూర్ణాంకాలు. ప్రారంభం ( ) ; కొత్త_అది ! = నా పూర్ణాంకాలు. ముగింపు ( ) ; కొత్త_అది ++ )
కోట్ << * కొత్త_అది << '' ;
తిరిగి 0 ;
}
అవుట్పుట్ :
కింది వాటిలో చూసినట్లుగా పూర్ణాంకాలు ఇక్కడ ఆరోహణ క్రమంలో చూపబడ్డాయి. మేము మునుపటి కోడ్లో “ఫర్” మరియు “ఆటో” అనే పదాలను ఉపయోగించాము కాబట్టి, మేము పూర్ణాంక సెట్లో ఉంచిన మొత్తం డేటా ఇక్కడ రెండర్ చేయబడుతుంది.

ఉదాహరణ 4:
మేము ఇక్కడ వెక్టర్స్తో పని చేస్తున్నప్పుడు “iostream” మరియు “vector” హెడర్ ఫైల్లు చేర్చబడ్డాయి. అప్పుడు “std” నేమ్స్పేస్ జోడించబడుతుంది మరియు మేము “ప్రధాన()” అని పిలుస్తాము. అప్పుడు, మేము 'int' డేటా రకం యొక్క వెక్టర్ను 'myVectorV1' పేరుతో ప్రారంభించాము మరియు ఈ వెక్టర్కి కొన్ని విలువలను జోడిస్తాము. ఇప్పుడు, మేము డేటా రకాన్ని గుర్తించడానికి ఇక్కడ “ఫర్” లూప్ని ఉంచాము మరియు “ఆటో”ను ఉపయోగిస్తాము. మేము వెక్టార్ విలువల ద్వారా యాక్సెస్ చేస్తాము మరియు 'కౌట్'లో 'valueOfVector'ని ఉంచడం ద్వారా వాటిని ప్రింట్ చేస్తాము.
దీని తర్వాత, మేము దాని లోపల మరొక 'ఫర్' మరియు 'ఆటో'ని ఉంచాము మరియు దానిని '&& valueOfVector : myVectorV1'తో ప్రారంభించాము. ఇక్కడ, మేము సూచన ద్వారా యాక్సెస్ చేసి, ఆపై 'cout'లో 'valueOfVector'ని ఉంచడం ద్వారా అన్ని విలువలను ప్రింట్ చేస్తాము. ఇప్పుడు, మేము లూప్లోని “ఆటో” కీవర్డ్ని ఉపయోగిస్తున్నందున మేము రెండు లూప్ల కోసం డేటా రకాన్ని చొప్పించాల్సిన అవసరం లేదు.
కోడ్ 4:
##
ఉపయోగించి నేమ్స్పేస్ std ;
int ప్రధాన ( ) {
వెక్టర్ < int > myVectorV1 = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
కోసం ( దానంతట అదే వెక్టర్ విలువ : myVectorV1 )
కోట్ << వెక్టర్ విలువ << '' ;
కోట్ << endl ;
కోసం ( దానంతట అదే && వెక్టర్ విలువ : myVectorV1 )
కోట్ << వెక్టర్ విలువ << '' ;
కోట్ << endl ;
తిరిగి 0 ;
}
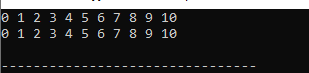
అవుట్పుట్:
వెక్టర్ యొక్క మొత్తం డేటా ప్రదర్శించబడుతుంది. మొదటి పంక్తిలో ప్రదర్శించబడే సంఖ్యలు మనం విలువల ద్వారా యాక్సెస్ చేసినవి మరియు రెండవ పంక్తిలో ప్రదర్శించబడే సంఖ్యలు కోడ్లోని సూచన ద్వారా మనం యాక్సెస్ చేసినవి.
ఉదాహరణ 5:
ఈ కోడ్లోని “ప్రధాన()” పద్ధతికి కాల్ చేసిన తర్వాత, మేము “7” పరిమాణంలోని “myFirstArray”ని “int” డేటా రకంతో మరియు “mySecondArray”ని “డబుల్” పరిమాణంతో “7”తో ప్రారంభిస్తాము. సమాచార తరహా. మేము రెండు శ్రేణులకు విలువలను ఇన్సర్ట్ చేస్తాము. మొదటి శ్రేణిలో, మేము 'పూర్ణాంకం' విలువలను ఇన్సర్ట్ చేస్తాము. రెండవ శ్రేణిలో, మేము 'డబుల్' విలువలను జోడిస్తాము. దీని తరువాత, మేము 'ఫర్' ను ఉపయోగించుకుంటాము మరియు ఈ లూప్లో 'ఆటో' ఇన్సర్ట్ చేస్తాము.
ఇక్కడ, మేము “myFirstArray” కోసం “range base for” లూప్ని ఉపయోగిస్తాము. అప్పుడు, మేము 'కౌట్' లో 'myVar' ను ఉంచుతాము. దీని క్రింద, మేము మళ్లీ ఒక లూప్ను ఉంచుతాము మరియు 'రేంజ్ బేస్ ఫర్' లూప్ను ఉపయోగించుకుంటాము. ఈ లూప్ “mySecondArray” కోసం మరియు ఆపై మేము ఆ శ్రేణి యొక్క విలువలను కూడా ముద్రిస్తాము.
కోడ్ 5:
#ఉపయోగించి నేమ్స్పేస్ std ;
int ప్రధాన ( )
{
int myFirstArray [ 7 ] = { పదిహేను , 25 , 35 , నాలుగు ఐదు , 55 , 65 , 75 } ;
రెట్టింపు mySecondArray [ 7 ] = { 2.64 , 6.45 , 8.5 , 2.5 , 4.5 , 6.7 , 8.9 } ;
కోసం ( స్థిరంగా దానంతట అదే & myVar : myFirstArray )
{
కోట్ << myVar << '' ;
}
కోట్ << endl ;
కోసం ( స్థిరంగా దానంతట అదే & myVar : mySecondArray )
{
కోట్ << myVar << '' ;
}
తిరిగి 0 ;
}
అవుట్పుట్:
రెండు వెక్టర్స్ యొక్క మొత్తం డేటా ఇక్కడ ఈ ఫలితంలో ప్రదర్శించబడుతుంది.

ముగింపు
'స్వయం కోసం' భావన ఈ వ్యాసంలో పూర్తిగా అధ్యయనం చేయబడింది. 'ఆటో' డేటా రకాన్ని పేర్కొనకుండానే గుర్తిస్తుందని మేము వివరించాము. మేము ఈ కథనంలో అనేక ఉదాహరణలను అన్వేషించాము మరియు ఇక్కడ కోడ్ వివరణను కూడా అందించాము. ఈ ఆర్టికల్లో ఈ “ఫర్ ఆటో” కాన్సెప్ట్ యొక్క పనిని మేము లోతుగా వివరించాము.