వారి IDల ఆధారంగా బహుళ JSON డాక్యుమెంట్లను పొందేందుకు ఎలాస్టిక్సెర్చ్ మల్టీ-గెట్ APIని ఎలా ఉపయోగించాలో ఈ కథనం చర్చిస్తుంది. అదనంగా, డాక్యుమెంట్ IDలను మాత్రమే ఉపయోగించి సూచికల నుండి డాక్యుమెంట్లను తిరిగి పొందడానికి ఒకే గెట్ క్వెరీని ఉపయోగించడానికి సాగే శోధన మిమ్మల్ని అనుమతిస్తుంది.
అన్వేషిద్దాం.
సింటాక్స్ని అభ్యర్థించండి
సాగే శోధన బహుళ-గెట్ API కోసం క్రింది వాక్యనిర్మాణం:
పొందండి /_mget
GET /
బహుళ-గెట్ API బహుళ సూచికలకు మద్దతు ఇస్తుంది, ఇది ఒకే సూచికలో లేనప్పటికీ పత్రాలను పొందేందుకు మిమ్మల్ని అనుమతిస్తుంది.
అభ్యర్థన క్రింది పాత్ పారామితులకు మద్దతు ఇస్తుంది:
- <సూచిక> – వారి IDల ద్వారా పేర్కొన్న పత్రాలను తిరిగి పొందే సూచిక పేరు.
చూపిన విధంగా మీరు ఇతర ప్రశ్న పారామితులను కూడా పేర్కొనవచ్చు:
- ప్రాధాన్యత - ఇష్టపడే నోడ్ లేదా షార్డ్ను నిర్వచిస్తుంది.
- రియల్ టైమ్ – ఒప్పుకు సెట్ చేస్తే, ఆపరేషన్ నిజ సమయంలో జరుగుతుంది.
- రిఫ్రెష్ చేయండి – నిర్దేశిత డాక్యుమెంట్లను పొందే ముందు టార్గెట్ షార్డ్లను రిఫ్రెష్ చేయడానికి ఆపరేషన్ను బలవంతం చేస్తుంది.
- రూటింగ్ - నిర్దిష్ట షార్డ్కు ఆపరేషన్లను రూట్ చేయడానికి ఉపయోగించే విలువ.
- స్టోర్_ఫీల్డ్లు – డాక్యుమెంట్లో కాకుండా ఇండెక్స్లో నిల్వ చేసిన డాక్యుమెంట్ ఫీల్డ్లను తిరిగి పొందుతుంది.
- _మూలం – అభ్యర్థన _source ఫీల్డ్ని తిరిగి ఇవ్వాలా వద్దా అని నిర్వచించే బూలియన్ విలువ.
ప్రశ్నకు శరీరం అవసరం, ఇందులో కింది విలువలు ఉంటాయి:
- డాక్స్ – మీరు పొందాలనుకుంటున్న పత్రాలను నిర్దేశిస్తుంది. అదనంగా, ఈ విభాగం క్రింది లక్షణాలకు మద్దతు ఇస్తుంది:
- _id – లక్ష్య పత్రం యొక్క ప్రత్యేక ID.
- _సూచిక – లక్ష్య పత్రాన్ని కలిగి ఉన్న సూచిక.
- రూటింగ్ – పత్రం యొక్క ప్రాథమిక భాగం కోసం కీ.
- _మూలం – నిజమైతే, అది అన్ని మూలాధార ఫీల్డ్లను కలిగి ఉంటుంది; లేకుంటే, అది వారిని మినహాయిస్తుంది.
- _నిల్వ చేసిన_క్షేత్రాలు – మీరు చేర్చాలనుకుంటున్న స్టోర్డ్_ఫీల్డ్లు.
- ఐడిలు – మీరు పొందాలనుకుంటున్న పత్రాల IDలు.
ఉదాహరణ 1: ఒకే సూచిక నుండి బహుళ పత్రాలను పొందండి
నెట్ఫ్లిక్స్ ఇండెక్స్ నుండి నిర్దిష్ట IDలతో పత్రాలను తిరిగి పొందడానికి Elasticsearch బహుళ-గెట్ APIని ఎలా ఉపయోగించాలో క్రింది ఉదాహరణ చూపిస్తుంది:
కర్ల్ -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: రిపోర్టింగ్' -H 'కంటెంట్-టైప్: అప్లికేషన్/json' -d'{
'డాక్స్': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
ఇచ్చిన అభ్యర్థన Netflix ఇండెక్స్ నుండి పేర్కొన్న IDలతో డాక్యుమెంట్లను పొందాలి. ఫలిత అవుట్పుట్ చూపిన విధంగా ఉంటుంది:
{'డాక్స్': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_వెర్షన్': 1,
'_seq_no': 0,
'_ప్రైమరీ_టర్మ్': 1,
'కనుగొంది': నిజం,
'_source': {
'వ్యవధి': '90 నిమి',
'listed_in': 'డాక్యుమెంటరీలు',
'దేశం': 'యునైటెడ్ స్టేట్స్',
'date_added': 'సెప్టెంబర్ 25, 2021',
'show_id': 's1',
'దర్శకుడు': 'కిర్స్టన్ జాన్సన్',
'విడుదల_సంవత్సరం': 2020,
'రేటింగ్': 'PG-13',
'వివరణ': 'ఆమె తండ్రి తన జీవితాంతం దగ్గర పడుతుండగా, చిత్రనిర్మాత కిర్స్టెన్ జాన్సన్ అతని మరణాన్ని కనిపెట్టి మరియు హాస్యాస్పదమైన మార్గాల్లో చేసి, వారిద్దరూ అనివార్యమైన వాటిని ఎదుర్కోవటానికి సహాయం చేస్తాడు.',
'రకం': 'సినిమా',
'శీర్షిక': 'డిక్ జాన్సన్ ఈజ్ డెడ్'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_వెర్షన్': 1,
'_seq_no': 12,
'_ప్రైమరీ_టర్మ్': 1,
'కనుగొంది': నిజం,
'_source': {
'దేశం': 'జర్మనీ, చెక్ రిపబ్లిక్',
'show_id': 's13',
'దర్శకుడు': 'క్రిస్టియన్ ష్వోచో',
'విడుదల_సంవత్సరం': 2021,
'రేటింగ్': 'TV-MA',
'వివరణ': 'ఆమె కుటుంబంలో చాలా మంది తీవ్రవాద బాంబు దాడిలో హత్య చేయబడిన తర్వాత, ఒక యువతి తెలియకుండానే వారిని చంపిన సమూహంలో చేరడానికి ఆకర్షించబడింది.',
'రకం': 'సినిమా',
'శీర్షిక': 'నేను కార్ల్',
'వ్యవధి': '127 నిమి',
'listed_in': 'నాటకాలు, అంతర్జాతీయ చలనచిత్రాలు',
'తారాగణం': 'లూనా వెడ్లర్, జానిస్ నీవోహ్నర్, మిలన్ పెషెల్, ఎడిన్ హసనోవిక్, అన్నా ఫియలోవా, మార్లోన్ బోస్, విక్టర్ బోకార్డ్, ఫ్లూర్ గెఫ్రియర్, అజీజ్ డయాబ్, మెలానీ ఫౌచె, ఎలిజవేటా మాక్సిమోవా',
'date_added': 'సెప్టెంబర్ 23, 2021'
}
}
]
}
కింది వాటిలో చూపిన విధంగా డాక్యుమెంట్ IDలను ఒక సాధారణ శ్రేణిలో ఉంచడం ద్వారా కూడా మేము అభ్యర్థనను సులభతరం చేయవచ్చు:
కర్ల్ -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: రిపోర్టింగ్' -H 'కంటెంట్-టైప్: అప్లికేషన్/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
మునుపటి అభ్యర్థన ఇదే విధమైన చర్యను అమలు చేయాలి.
ఉదాహరణ 2: బహుళ సూచికల నుండి పత్రాలను పొందండి
కింది ఉదాహరణలో, అభ్యర్థన చూపిన విధంగా వివిధ సూచికల నుండి బహుళ పత్రాలను పొందుతుంది:
కర్ల్ -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: రిపోర్టింగ్' -H 'కంటెంట్-టైప్: అప్లికేషన్/json' -d'{
'డాక్స్': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'డిస్నీ',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
ఫలిత అవుట్పుట్ చూపిన విధంగా ఉంటుంది:

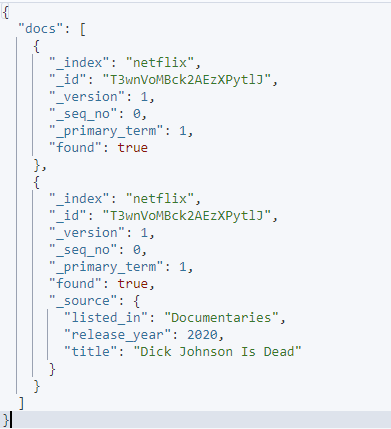
ఉదాహరణ 3: నిర్దిష్ట ఫీల్డ్లను మినహాయించండి
మేము source_include మరియు source_exclude పారామితులను ఉపయోగించి ఇచ్చిన అభ్యర్థన నుండి నిర్దిష్ట ఫీల్డ్లను మినహాయించవచ్చు.
చూపిన విధంగా ఒక ఉదాహరణ:
కర్ల్ -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: రిపోర్టింగ్' -H 'కంటెంట్-టైప్: అప్లికేషన్/json' -d'{
'డాక్స్': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': తప్పు
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'మినహాయింపు': [ 'వివరణ', 'రకం', 'తేదీ_జోడించబడింది' ]
}
}
]
}'
మీరు ఇచ్చిన పత్రంలో ఏయే ఫీల్డ్లను తిరిగి పొందాలనుకుంటున్నారో పేర్కొనడానికి అందించిన అభ్యర్థన మూలాధారాన్ని ఉపయోగిస్తుంది మరియు మినహాయించబడుతుంది.
ఫలిత అవుట్పుట్ చూపిన విధంగా ఉంటుంది:
ముగింపు
ఈ పోస్ట్లో, మేము వారి IDల ఆధారంగా వివిధ మూలాధారాల నుండి బహుళ డాక్యుమెంట్లను పొందేందుకు మిమ్మల్ని అనుమతించే Elasticsearch బహుళ-గెట్ APIతో పని చేసే ప్రాథమిక అంశాలను చర్చించాము. మరింత సమాచారం కోసం ఇతర పత్రాలను అన్వేషించడానికి సంకోచించకండి.
హ్యాపీ కోడింగ్!